- Python数据分析教程导航
- Python - 操作 MySQL 数据库
- Python 数据分析教程
- Python 数据分析
- NumPy数值计算基础
- Python ndarray
- Python NumPy矩阵
- 利用NumPy进行统计分析
- Python pandas基础
- Python pandas数据结构
- Python pandas基本功能
- Python pandas描述性统计
- Python 数据读取、存储与⽂件格式
- 文本格式数据的读写
- Python 二进制格式
- 数据清洗与准备
- Python 处理缺失值
- Python 数据转换
- 字符串操作
- 分层索引
- 联合与合并数据集
- Python 数据重塑和数据透视
- Python Matplotlib数据可视化基础
- Python 常用绘图库原理及示例
- Python 用pandas和seaborn绘图
- Python 可视化工具概览
- Python Pandas的分组聚合操作
- GroupBy机制
- 数据聚合
- Python 数据透视表与交叉表
- 时间序列
- 日期和时间数据的类型及工具
- 时间序列基础
- 日期范围、频率和移位
- 时区处理
- 时间区间和区间算术
- 重新采样与频率转换
- 移动窗口函数
- Python pandas分类数据
- 分类数据
- Python GroupBy进阶
- Python 方法链技术
- Python建模库介绍
- Python pandas与建模代码的结合
- statsmodels介绍
- Python 使用sklearn转换器处理数据
- Python 构建并评价聚类模型
- Python 构建并评价分类模型
- 构建并评价回归模型
- Python ndarray对象内幕
- 高阶数组操作
- Python 广播
- Python 高阶ufunc用法
- Python 排序
- Python 回归分析
- 回归分析的基本原理
- 一元线性回归
- 非线性回归
- 多项式回归
Python 构建并评价聚类模型
1 概述
聚类分析是在没有给定划分类别的情况下,根据数据相似度进行样本分组的一种方法。聚类模型可以将无类标记的数据聚集为多个簇,视为一类,是一种非监督的学习算法。在商业上,聚类可以帮助市场分析人员从消费者数据库中区分出不同的消费群体,并且概括出每一类消费者的消费模式或消费习惯。同时,聚类分析也可以作为数据分析算法中其他分析算法的一个预处理步骤,如异常值识别、连续型特征离散化等。
2 使用sklearn估计器构建聚类模型
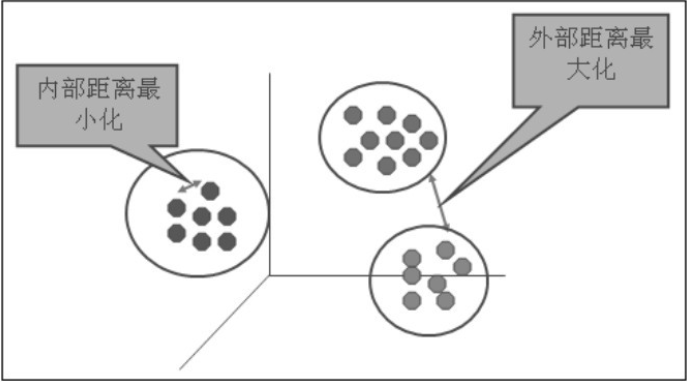
聚类的输入是一组未被标记的样本,聚类根据数据自身的距离或相似度将它们划分为若干组,划分的原则是组内(内部)距离最小化,而组间(外部)距离最大化,如下图所示。
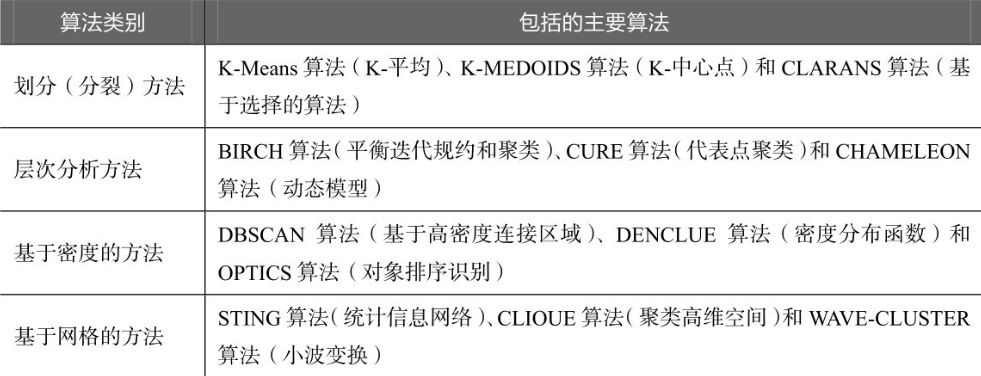
常用的聚类算法如下表所示。
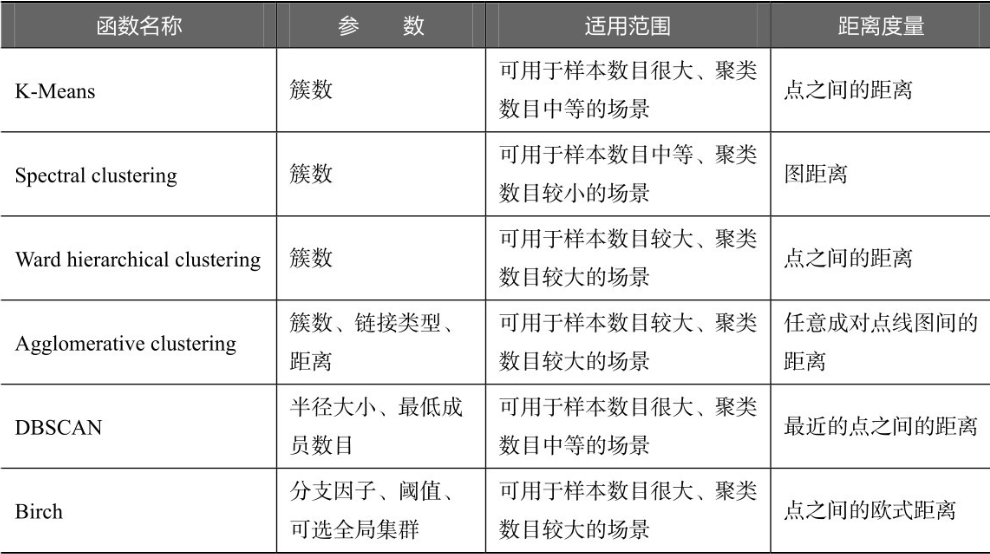
sklearn常用的聚类算法模块cluster提供的聚类算法及其适用范围如下表所示。
聚类算法实现需要sklearn估计器(Estimator)。sklearn估计器拥有fit和predict两个方法。

以iris数据为例,使用sklearn估计器构建 K-Means聚类模型。
聚类完成后需要通过可视化的方式查看聚类效果,通过 sklearn 的 manifold 模块中的TSNE函数可以实现多维数据的可视化展现。使用TSNE函数对代码6-10中的结果做可视化。
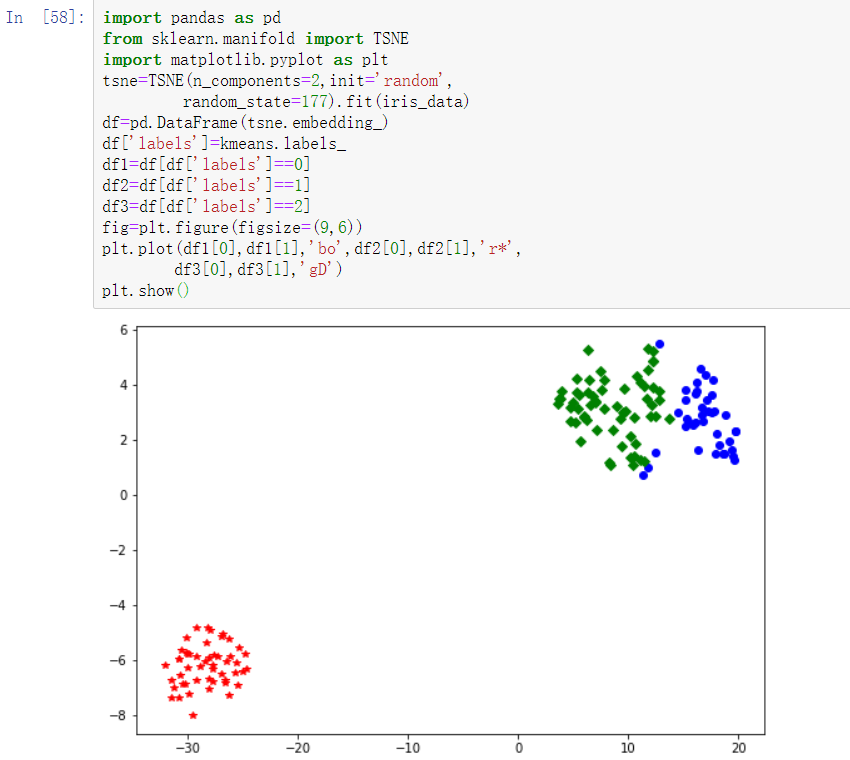
本次聚类类别分布比较均匀,不同类别数目差别不大。除个别点以外,类与类间的界限明显,聚类效果良好。
3 评价聚类模型
聚类评价的标准是组内的对象相互之间是相似的(相关的),而不同组中的对象是不同的(不相关的)。即组内的相似性越大,组间差别越大,聚类效果就越好。sklearn的metrics模块提供的聚类模型评价指标如下表所示。
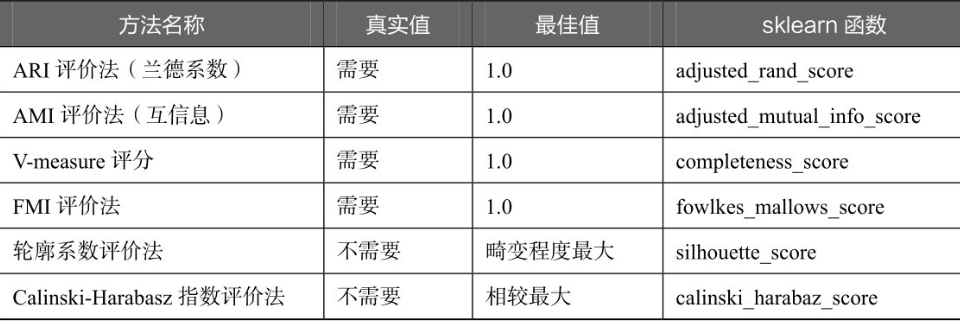
上表中总共列出了6种评价的方法,其中,前4种方法均需要真实值的配合才能够评价聚类算法的优劣,后两种则不需要真实值的配合。但是前4种方法评价的效果更具有说服力,并且在实际运行的过程中,在有真实值做参考的情况下,聚类方法的评价可以等同于分类算法的评价。
除了轮廓系数评价法以外的评价方法,在不考虑业务场景的情况下都是得分越高,其效果越好,最高分值为 1。而轮廓系数评价法则需要判断不同类别数目情况下的轮廓系数的走势,寻找最优的聚类数目。
在需要真实值配合的聚类评价方法中选取FMI评价法判定建立的K-Means聚类模型。
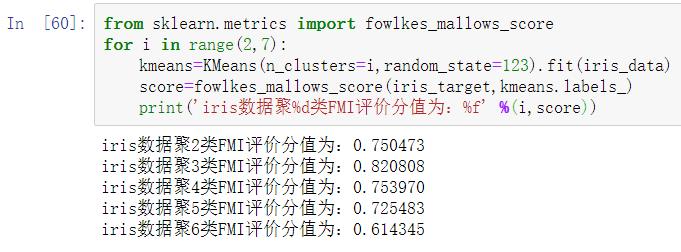
iris数据聚3类的时候FMI评价法分值最高,故聚类为3类的时候K-Means聚类模型最好。
使用轮廓系数评价法评估K-Means模型,然后做出轮廓系数走势图,根据图形判断聚类效果。
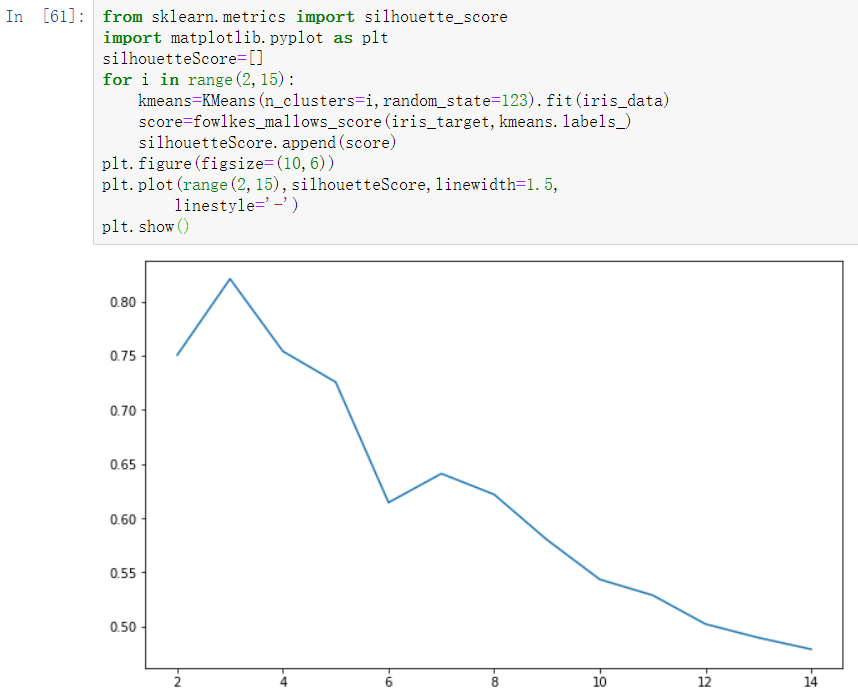
聚类数目为2、3和5、6时平均畸变程度最大。由于iris数据本身就是3种鸢尾花的花瓣、花萼长度和宽度的数据,侧面说明了聚类数目为3的时候效果最佳。
使用Calinski-Harabasz指数评价K-Means聚类模型,其基本判定方法和前4种需要真实值作为依据的方法相同,分值越高,聚类效果越好。
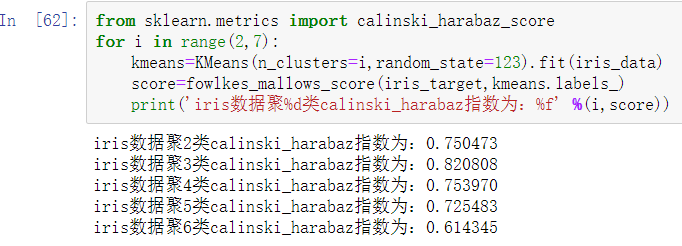
Calinski-Harabasz指数评价K-Means聚类模型的时候,聚类数目为3的时候得分最高,所以可以认为iris数据聚类为3类的时候效果最优。
综合以上聚类评价方法,在真实值作为参考的情况下,几种方法均可以很好地评估聚类模型。在没有真实值作为参考的时候,轮廓系数评价法和 Calinski-Harabasz 指数评价法可以结合使用。

