- Python数据分析教程导航
- Python - 操作 MySQL 数据库
- Python 数据分析教程
- Python 数据分析
- NumPy数值计算基础
- Python ndarray
- Python NumPy矩阵
- 利用NumPy进行统计分析
- Python pandas基础
- Python pandas数据结构
- Python pandas基本功能
- Python pandas描述性统计
- Python 数据读取、存储与⽂件格式
- 文本格式数据的读写
- Python 二进制格式
- 数据清洗与准备
- Python 处理缺失值
- Python 数据转换
- 字符串操作
- 分层索引
- 联合与合并数据集
- Python 数据重塑和数据透视
- Python Matplotlib数据可视化基础
- Python 常用绘图库原理及示例
- Python 用pandas和seaborn绘图
- Python 可视化工具概览
- Python Pandas的分组聚合操作
- GroupBy机制
- 数据聚合
- Python 数据透视表与交叉表
- 时间序列
- 日期和时间数据的类型及工具
- 时间序列基础
- 日期范围、频率和移位
- 时区处理
- 时间区间和区间算术
- 重新采样与频率转换
- 移动窗口函数
- Python pandas分类数据
- 分类数据
- Python GroupBy进阶
- Python 方法链技术
- Python建模库介绍
- Python pandas与建模代码的结合
- statsmodels介绍
- Python 使用sklearn转换器处理数据
- Python 构建并评价聚类模型
- Python 构建并评价分类模型
- 构建并评价回归模型
- Python ndarray对象内幕
- 高阶数组操作
- Python 广播
- Python 高阶ufunc用法
- Python 排序
- Python 回归分析
- 回归分析的基本原理
- 一元线性回归
- 非线性回归
- 多项式回归
字符串操作
字符串操作
由于Python在字符串和文本操作上的便利性,使Python成为一个流行的原生数据集操作语言已经有很长时间了。字符串对象的内建方法使得大部分文本操作非常简单。对于更为复杂的模式匹配和文本操作,正则表达式可能是需要的。
1、字符串对象方法
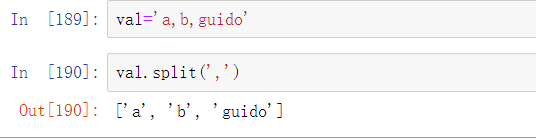
在很多字符串处理和脚本应用中,内建的字符串方法是足够的。例如,一个逗号分隔的字符串可以使用split方法拆分成多块:
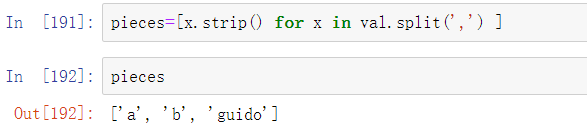
split常和strip一起使用,用于清除空格(包括换行):
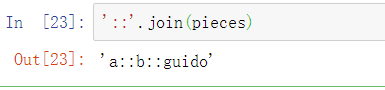
这些子字符串可以使用加法与两个冒号分隔符连接在一起:

但是这并不是一个实用的通用方法。在字符串’ : : ’的join方法中传入一个列表或元组是一种更快且更加Pythonic(Python风格化)的方法:
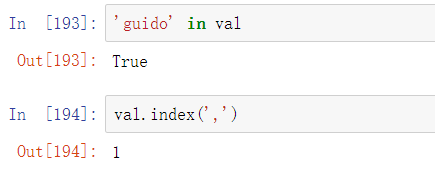
其他方法涉及定位子字符串。使用Python的in关键字是检测子字符串的最佳方法,尽管index和find也能实现同样的功能:
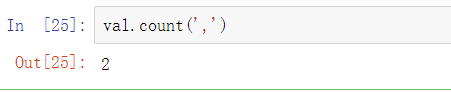
相关地,count返回的是某个特定的子字符串在字符串中出现的次数:
replace将用一种模式替代另一种模式。它通常也用于传入空字符串来删除某个模式。

下表是一些Python字符串方法的列表。

2、正则表达式
正则表达式提供了一种在文本中灵活查找或匹配(通常更为复杂的)字符串模式的方法。单个表达式通常被称为regex,是根据正则表达式语言形成的字符串。Python内建的re模块是用于将正则表达式应用到字符串上的库。
re模块主要有三个主题:模式匹配、替代、拆分。当然,这三部分主题是相关联的。一个正则表达式描述了在文本中需要定位的一种模式,可以用于多种目标。
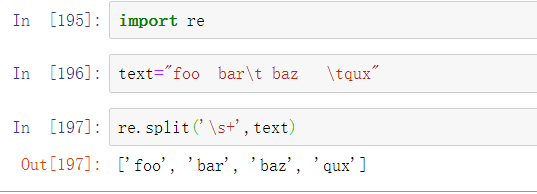
当你调用re.split(‘\s+’, text),正则表达式首先会被编译,然后正则表达式的split方法在传入文本上被调用。你可以使用re.compile自行编译,形成一个可复用的正则表达式对象:

如果想获得的是一个所有匹配正则表达式的模式的列表,你可以使用findall方法:

注意:为了在正则表达式中避免转义符\的影响,可以使用原生字符串语法,比如r’C:\x’或者用等价的’C:\x’。
match和search与findall相关性很大。findall返回的是字符串中所有的匹配项,而search返回的仅仅是第一个匹配项。match更为严格,它只在字符串的起始位置进行匹配。
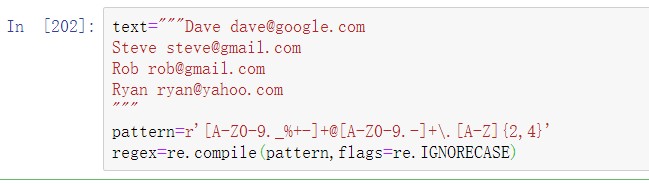
在文本上使用findall会生成一个电子邮件地址的列表:

search返回的是文本中第一个匹配到的电子邮件地址。对于前面提到的正则表达式,匹配对象只能告诉我们模式在字符串中起始和结束的位置:

3、pandas中的向量化字符串函数
清理杂乱的数据集用于分析通常需要大量的字符串处理和正则化。包含字符串的列有时会含有缺失数据,使事情变得复杂:
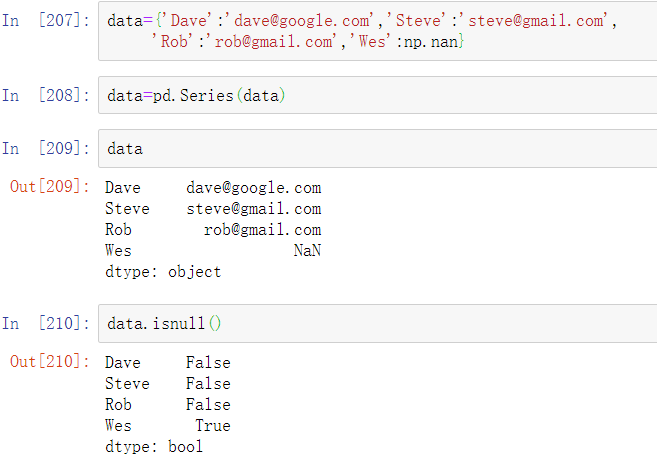
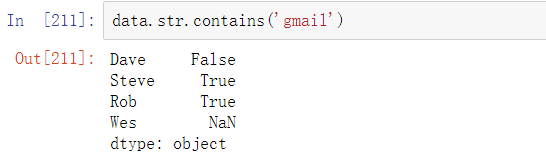
可以使用data.map将字符串和有效的正则表达式方法(以lambda或其他函数的方式传递)应用到每个值上,但是在NA(null)值上会失败。为了解决这个问题,Series有面向数组的方法用于跳过NA值的字符串操作。这些方法通过Series的str属性进行调用,例如,我们可以通过str.contains来检查每个电子邮件地址是否含有’gmail’:
下表中有更多pandas字符串方法。


