- OLAP工具 - Kylin导航
- 杂谈 - Apache Kylin5年的成长与未来规划
- Kylin 简介
- Kylin 安装
- Kylin 无Hadoop环境部署Kylin4
- Kylin 集群模式部署
- Kylin 用Docker运行Kylin
- Kylin Web界面
- Kylin Cube创建
- Kylin Cube构建和Job监控
- Kylin SQL快速参考
- Kylin 项目和表级别权限控制
- Kylin Python客户端
- Kylin 建立系统Cube
- Kylin Cube Planner
- Kylin 使用Dashboard
- Kylin 基于Mysql的Metastore配置
- Kylin 查询下压
- Kylin ODBC驱动
- Kylin JDBC驱动
- Kylin Tableau 8
- Kylin Tableau 9
- Kylin Excel及 Power BI教程
- Kylin Qlik Sense 集成
- Kylin Superset可视化平台
杂谈 – Apache Kylin5年的成长与未来规划
ApacheKylin5周年庆祝活动于2020年12月19日顺利结束。这次会议上,ApacheKylinPMCChair史少锋先生与大家分享了Kylin在过去5年里的成长和Kylin4.0开发的现状,同时也向社区分享Kylin未来的发展计划。

史少锋先生在现场为大家做了直播。
1 Apache Kylin 5 Year Milestone
在2015年末,Kylin正式从Apache软件基金会毕业,成为中国首个Apache顶级开源项目。近5年来,Kylin社区不断发展壮大,拥有极其活跃的技术社区,协作开发,推动Kylin成为一款高效的、数据分析型数据仓库。
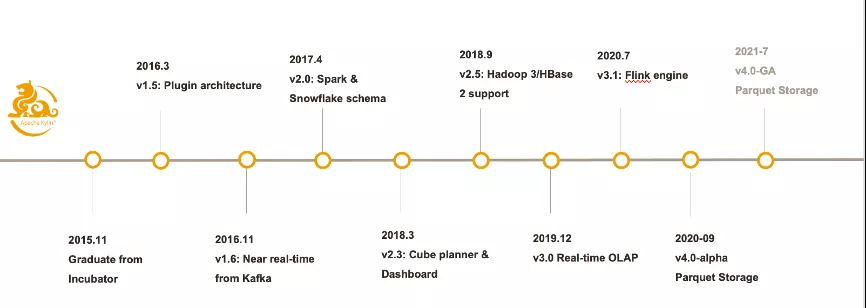
1.1 Kylin技术发展概况
Kylin1.5版在2016年初支持Plug-in体系结构。
这对于将来开发更多的数据源.构建引擎和存储引擎有很好的基础。
在2016年年底,Kylin1.6版对Kafka实时数据源提供了支持。
数据在微批中被加载,极大地减少了数据加载的延时,由原来的天级或数小时级变为分钟级。
- Kylin2.0在2017年4月发布。
官方支持Spark作为构建引擎,并加入了雪花模型的支持。
- 2018年3月,eBay团队提供了CubePlanner和Dashboard。
相比以前,KylinCube优化更加方便,用户可以取样并分析数据,让算法来决定哪种Cuboid需要计算,再次利用Dashboard中收集的查询历史,使Cube进一步优化,从而极大地提高了性能和存储空间。
- 2018年9月,2.5版支持Hadoop3.0和HBase2.0。
将延迟从分钟级进一步降低到秒级。Kylin也从那时起支持历史查询、准实时查询和实时查询。
- 2020中期Kylin3.1发行版。
对Flink作为计算引擎提供了支持,至此,MapReduce.Spark和Flink都与Kylin对接,用户可以根据自己的喜好选择适合的引擎进行Cube计算。
- 在2020年九月,Kylin4.0Alpha版正式发布。
新的构建引擎和查询引擎大大提高了构建性能和查询性能,解决了查询单点等难点问题;消除HBase依赖,在很大程度上解决了Kylin难以操作的问题,使Kylin实现计算、存储分离成为可能。
1.2 Kylin社区发展
Kylin在过去的5年里抓住了大量的用户,并广泛地应用于数据分析和报告显示方面,用户群不仅包括eBay、Yahoo日本、美团、网易等一些互联网厂商,这其中还有小米、华为、VIVO等制造厂商;此外,还有一批国外用户,比如VISA、CISCO、迪卡侬、沃达丰等等。

Kylin的社区在这5年里也不断成长壮大,2015年只有16名开发者,那时Kylin发布了5个版本,自那时起,Kylin社区不断壮大,截至2020年12月,已有44个Committer,包括24个PMCMembers,此外,CodeContributors超过180位。
2015至2020年,Kylin发布了36个ApacheRelease,平均每年发布6-7个版本。此外,社区的活跃程度还可以通过JiraIssue和GitHubStar获得概述。
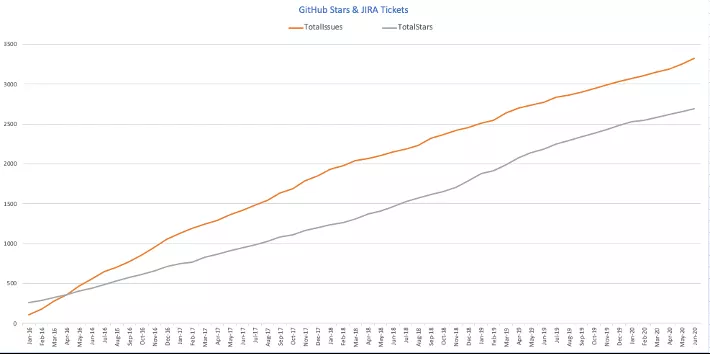
JIRAissue可以从这条曲线看出,每年有很多用户在Kylin社区中活跃,而GitHubStar的数量也不断增加。
2 最新版本 Apache Kylin 4.0
2.1 Kylin 4.0 开发节点
开始时,Kylin4.0测试版最早将于本月底或2021年初面世,GA版将于2021年中发布。

Kylin4.0改革的一大目标是用Parquet存储取代HBase存储。HBase的功能比较复杂,它给Kylin的运维带来了很大的挑战,同时也给企业的维护和扩展成本增加了。Kylin希望将来能够发展成为独立的存储和计算体系结构,以帮助用户更轻松地进行维护。Cube的计算引擎和查询引擎将全部替换为Spark,整个体系结构也是基于Kylin的可插入架构实现的,但由于存储是一个非常基本的模块,因此对于较高层次和较低层次来说,都存在很多变化。
现在,Kylin网站4.0Alpha已经发布了,有兴趣的小伙伴可以登陆网站下载预览,基本功能包括Cube计算与查询,相对来说比较完整。
有望于本月底或2021年初正式发布4.0Beta版,同时也在开发更先进的特性,并与包括CubePlanner.Dashboard在内的新的存储和查询引擎进行性能优化。
到明年(2021年)中旬,4.0GA版本将继续增加与Kafka的数据源对接,并实现Spark3.0的升级,而其他一些高级功能也将在GA版中与大家见面。
2.2 Kylin4.0的业绩概述
之后,我们将重点展示Kylin4.0和3.0在线下进行Cube计算性能的对比,以及在线SQL查询的性能对比。
① 脱机计算的Cube性能
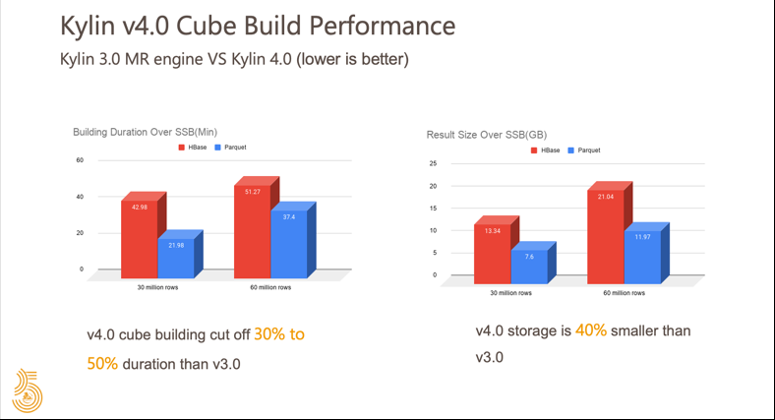
先看下下Cube计算的性能,左图显示构建时间的对比,用3.0的MapReduce引擎和4.0的Spark引擎做对比,我们可能会发现,与3.0版相比,4.0会降低30%-50%,也就是4.0版Cube构建的速度会是3.0版本的两倍。
就存储而言,右面图表显示Cube4.0版将比3.0降低近40%,因为3.0版Cube将存储2个Cube数据,一个HDFS上的中间结果将用于将来的segment合并,另外一个文件用于HBase中的查询;但是4.0版本中,您只需要使用Parquet数据的一份进行合并和查询。因此4.0存储空间大约是3.0的1/3。
② 在线SQL查询的执行
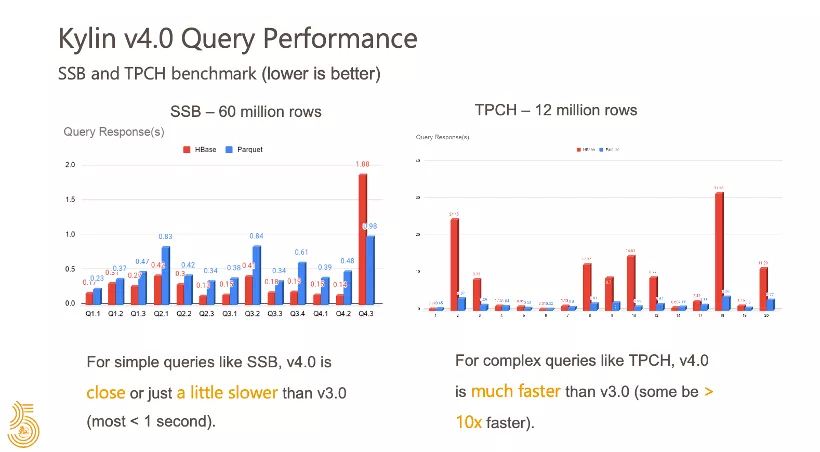
上面的对比使用了两个典型的Benchmark数据,左边是SSB数据集,这是一个相对简单的分析场景。在大部分简单场景的查询中,从左边的图片可以看出,4.0与3.0的性能比较接近,但是3.0的查询速度略慢一些,3.0的查询时间大约为0.5秒,4.0比3.0稍慢0.2.0.3。
右下角是复杂的TPCH模型,查询将更加复杂,可以看到3.0上许多查询响应几乎都在10秒或20-30秒之间,但是Kylin4.0通过利用Spark的分布式计算和分布式聚合,进一步分散了Kylin的query节点的负载(并且不再使用字典加载和解码),通过进一步提高了查询性能,图中可以清楚地看到,在某些缓慢的查询上,Kylin4.0比3.0的性能提高了近10倍。
总而言之,Kylin 4.0 的性能比 3.0 在小而简单的查询下基本持平,但是在复杂且慢查询下会有非常大幅度的提升。
3 Apache Kylin 未来展望
3.1 Cloud-Native
随着云计算的普及,过去可能很多原本只能在 Hadoop 上做的事情有了新的选择。但云随之而来给企业的应用,特别是给 IT 架构带来很大的变化。
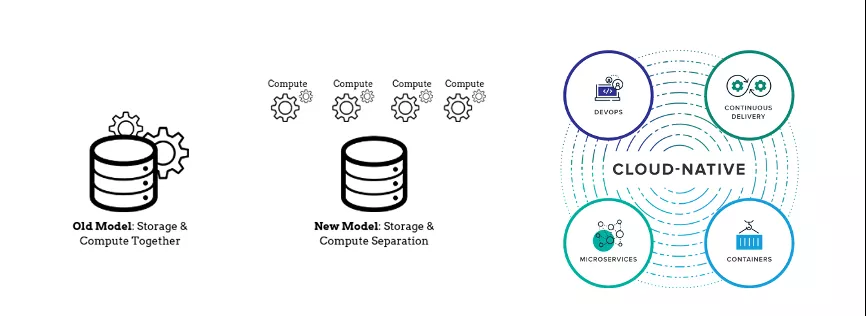
现在越来越多的企业正在拥抱云原生(Cloud-Native)架构,目的是让企业能更适应于在云上部署。对于 Kylin 而言,Kylin 也会做计算和存储分离,这样就能让计算资源和存储资源分别独立的弹性伸缩,从而实现资源的更高效利用。
另一方面,为了能实现应用之间更好的隔离,促进应用往更高性能、更高稳定性发展,我们也希望对 Kylin 整体架构的调整能更好得在云上部署,来使用云原生的存储计算的框架,以及监控运维的框架。在这方面可以看到最火的就是以 Kubernetes 为代表的容器编排技术,以及云上以 S3 所代表的新的分布式对象存储技术。
3.2 实时分析(Real-time)
过去大数据处理大部分是使用批处理来对数据做加工、清洗和聚合;因为批处理相对来说比较简单,以及高吞吐的经济效率比较高。但是批处理最大问题在于数据的延迟比较久,通常在 T+1,就是1天或者是若干个小时之后才能看到这个数据分析的结果。
今天越来越多的企业对数据时效性提出了更高要求,业务希望数据的处理时间能够降低在分钟级甚至是秒级,这些年可以看到实时计算的技术越来越火,包括Spark Structed Streaming、Flink 以及一些其它的流计算框架。对 OLAP 来说,未来我们希望 Kylin 一方面能够继续支持批量的数据加载,另一方面也能支持流数据的处理,实现流批一体化。
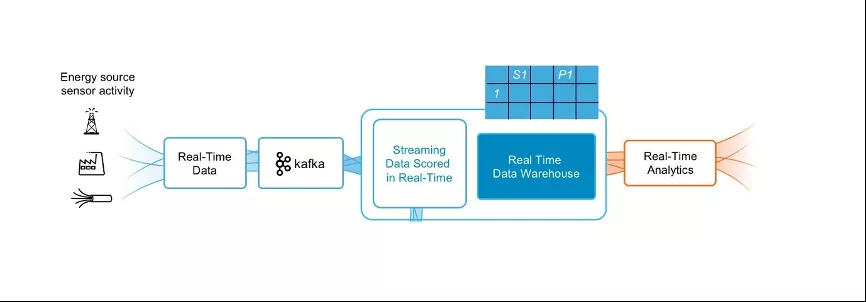
大家可以从 Kylin3.0 版本就能看到,我们统一了流计算和批计算,未来用户只用运维一套 OLAP 平台就可以服务不同的场景。
3.3 人工智能与机器学习
人工智能就是让机器学会人的思考方式,通过模型的训练让机器可以自动的做出判断决策,从而减少人工的投入,提高人类的工作效率。如何才能让 AI 更加的智能,模型更加的准确,成熟度更高?在这背后就需要更多的数据进行训练,而这就是大数据与机器学习所结合的价值所在。
Kylin 过去主要服务的场景是在 BI 领域,也就是说把数据采集出来,通过对接 BI 赋能分析人员来看到数据中发生了哪些本质的变化。在未来我们希望 Kylin 可以通过这些数据来赋能于 AI,能直接从数据中挖掘出来价值告诉人类,而不是让人通过 BI 来获取这些信息。
4 总结
最后我们总结未来对 Kylin 的期待。
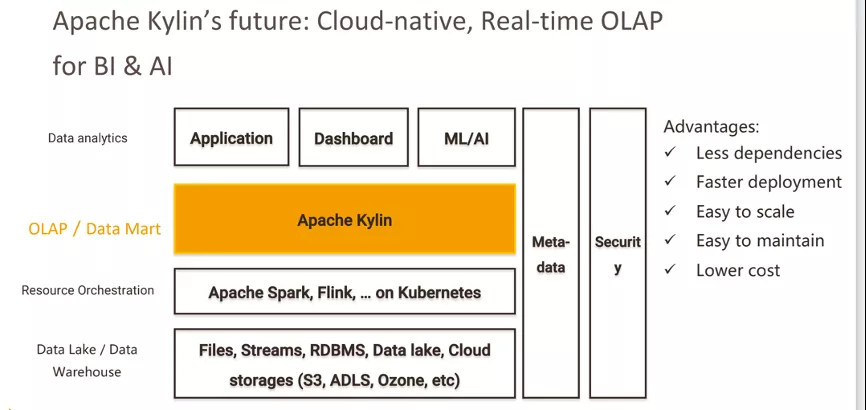
我们希望 Kylin 能成长为一个云原生的,可以支持批处理以及流处理的分析型数据仓库。一方面能服务于 BI,另一方面可以实现对 AI 的支持,相比于其它技术和引擎来说,它在高性能和高并发上具有明显的优势。未来它的底层架构可以直接运行在轻量级的分布式计算框架上,也可以直接部署在容器上,可以对接多种数据源,包括文件集合,实时流,传统的 RDBMS,或是现在很热门的数据湖。此外未来也希望 Kylin 的部署、运维、监控、扩容、缩容都会变得更加容易,最终也可以让用户的总体成本比以前有一个大幅降低。
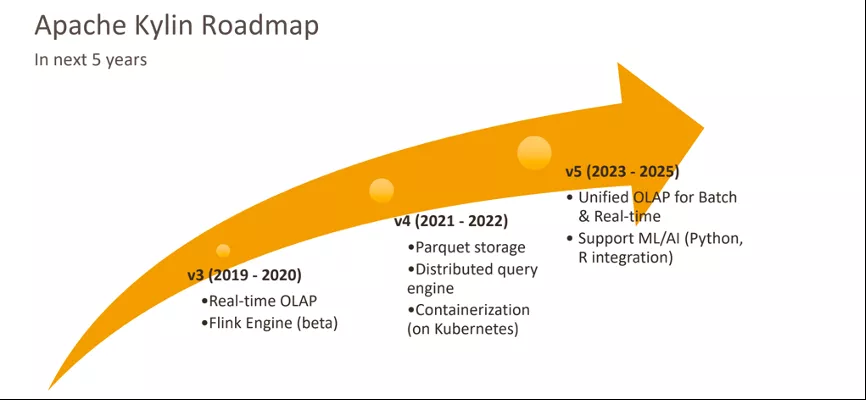
到 Kylin 5.0 的时候,我们希望它能够基于Cloud-Native 架构再次统一流批 OLAP 分析,并实现对 Machine Learning 及 AI 的支持。
5 关于作者
史少锋,Kyligence 合伙人 & 首席软件架构师,Apache Kylin 核心开发者和项目管理委员会主席 (PMC Chair),专注于大数据分析和云计算技术。曾任eBay全球分析基础架构部大数据高级工程师,IBM云计算软件架构师。


评论区(0)