- OLAP工具 - Presto导航
- Presto 简介
- Presto 相关概念
- Presto 安装及运行
- Presto 使用JDBC驱动访问
- Presto Tableau连接Presto
- Presto Spark执行Presto任务
- Presto Druid Connector
- Presto Hive Connector
- Presto JMX Connector
- Presto Kafka Connector
- Presto MongoDB Connector
- Presto Mysql Connector
- Presto Oracle Connector
- Presto PostgreSQL Connector
- Presto Redis Connector
- Presto SQL Server Connector
- Presto Local File Connector
- Presto System Connector
- Presto 从Hive迁移
Presto 简介
OLAP数据查询引擎
大规模并行处理模型(Massively parallel processing,MPP)
- Presto的优点
支持不同数据源
支持SQL查询
扩展性强
支持混合计算
高性能
PipeLine式设计
- Presto的缺点
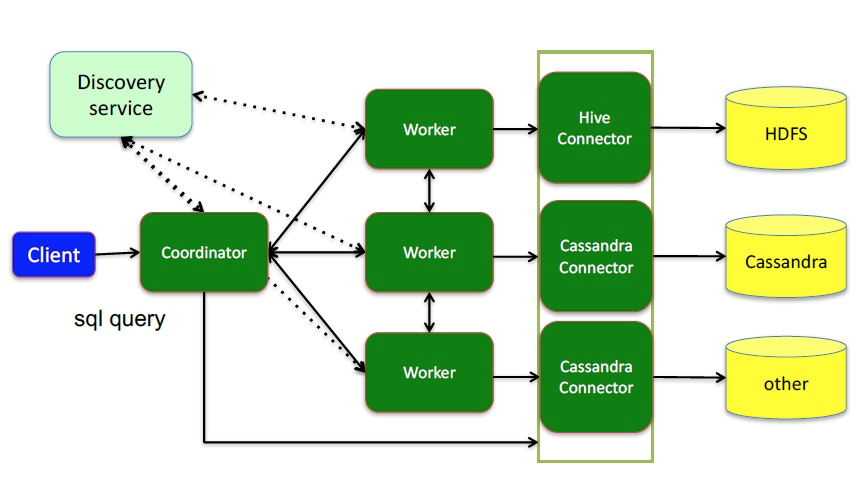
- Coordinator
解析语句规划查询管理Presto工作节点一个Coordinator一个或多个Worker
- Worker
orker负责执行任务和处理数据。节点从获取数据并相互交换中间数据。负责从那里获取结果并将最终结果返回给客户端。
- connector
插件形式数据存储层Hive关系性数据库
- discovery service

