- Python数据分析教程导航
- Python - 操作 MySQL 数据库
- Python 数据分析教程
- Python 数据分析
- NumPy数值计算基础
- Python ndarray
- Python NumPy矩阵
- 利用NumPy进行统计分析
- Python pandas基础
- Python pandas数据结构
- Python pandas基本功能
- Python pandas描述性统计
- Python 数据读取、存储与⽂件格式
- 文本格式数据的读写
- Python 二进制格式
- 数据清洗与准备
- Python 处理缺失值
- Python 数据转换
- 字符串操作
- 分层索引
- 联合与合并数据集
- Python 数据重塑和数据透视
- Python Matplotlib数据可视化基础
- Python 常用绘图库原理及示例
- Python 用pandas和seaborn绘图
- Python 可视化工具概览
- Python Pandas的分组聚合操作
- GroupBy机制
- 数据聚合
- Python 数据透视表与交叉表
- 时间序列
- 日期和时间数据的类型及工具
- 时间序列基础
- 日期范围、频率和移位
- 时区处理
- 时间区间和区间算术
- 重新采样与频率转换
- 移动窗口函数
- Python pandas分类数据
- 分类数据
- Python GroupBy进阶
- Python 方法链技术
- Python建模库介绍
- Python pandas与建模代码的结合
- statsmodels介绍
- Python 使用sklearn转换器处理数据
- Python 构建并评价聚类模型
- Python 构建并评价分类模型
- 构建并评价回归模型
- Python ndarray对象内幕
- 高阶数组操作
- Python 广播
- Python 高阶ufunc用法
- Python 排序
- Python 回归分析
- 回归分析的基本原理
- 一元线性回归
- 非线性回归
- 多项式回归
联合与合并数据集
联合与合并数据集
包含在pandas对象的数据可以通过多种方式联合在一起:
- pandas.merge根据一个或多个键将行进行连接。对于SQL或其他关系型数据库的用户来说,这种方式比较熟悉,它实现的是数据库的连接操作。
- pandas.concat使对象在轴向上进行黏合或“堆叠”。
- combine_first实例方法允许将重叠的数据拼接在一起,以使用一个对象中的值填充另一个对象中的缺失值。
1、数据库风格的DataFrame连接
合并或连接操作通过一个或多个键连接行来联合数据集。这些操作是关系型数据库的核心内容(例如基于SQL的数据库)。pandas中的merge函数主要用于将各种join操作算法运用在你的数据上:
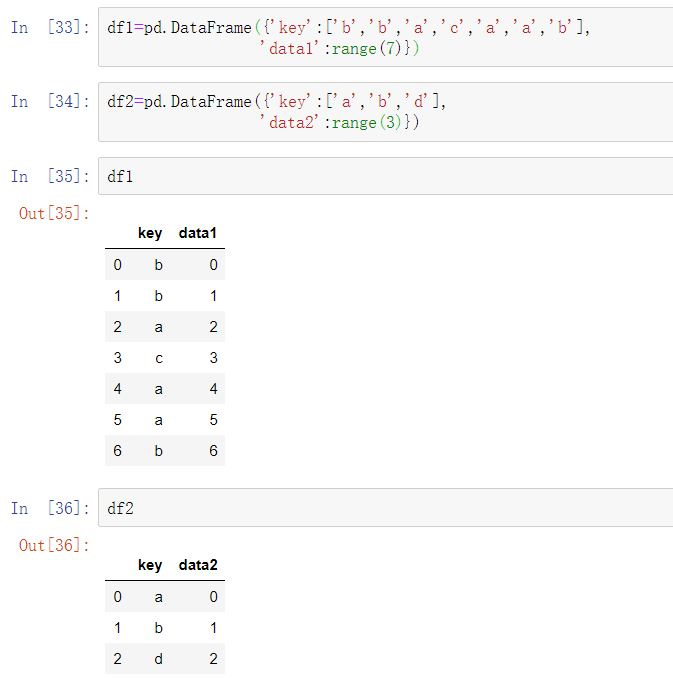
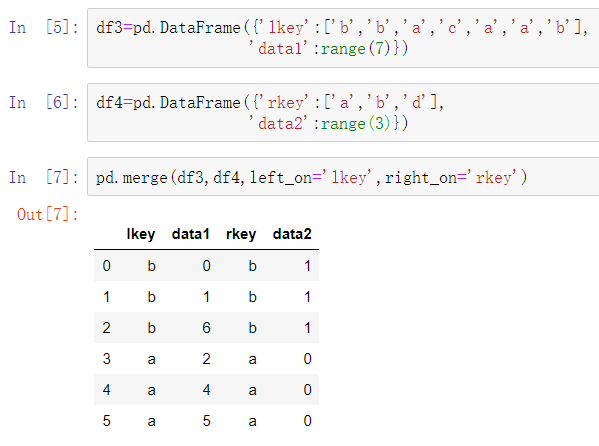
这是一个多对一连接的例子;df1的数据有多个行的标签为a和b,而df2在key列中每个值仅有一行。调用merge处理我们获得的对象:
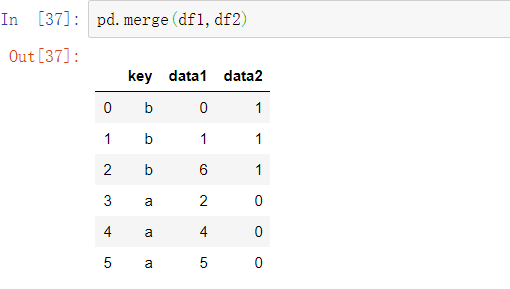
并没有指定在哪一列上进行连接。如果连接的键信息没有指定,merge会自动将重叠列名作为连接的键。但是,显式地指定连接键才是好的实现:
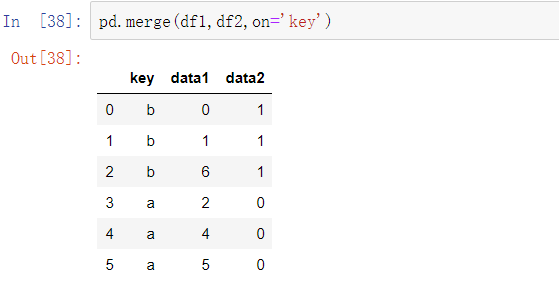
如果每个对象的列名是不同的,你可以分别为它们指定列名:
默认情况下,merge做的是内连接(’inner’join),结果中的键是两张表的交集。其他可选的选项有’left’、’right’和’outer’。外连接(outer join)是键的并集,联合了左连接和右连接的效果:
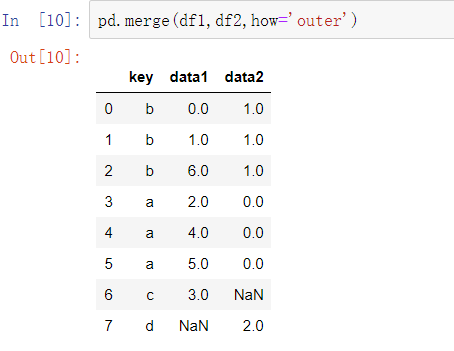
下表是对how选项的总结。

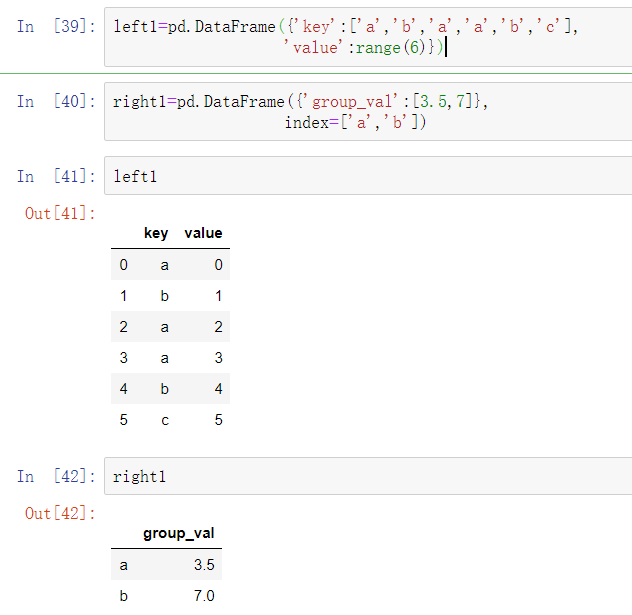
2、根据索引合并
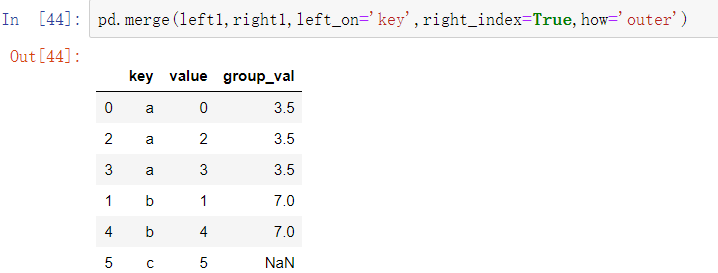
在某些情况下,DataFrame中用于合并的键是它的索引。在这种情况下,你可以传递left_index=True或right_index=True(或者都传)来表示索引需要用来作为合并的键:
由于默认的合并方法是连接键相交,可以使用外连接来进行合并:
3、沿轴向连接
另一种数据组合操作可互换地称为拼接、绑定或堆叠。NumPy的concatenate函数可以在NumPy数组上实现该功能:
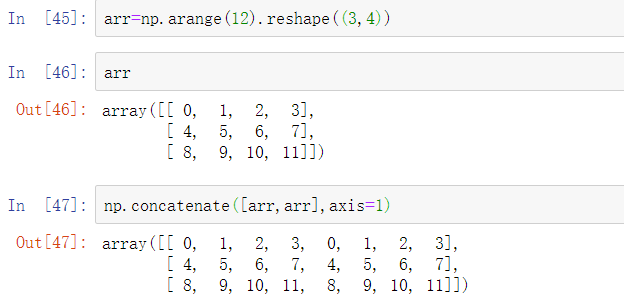
在Series和DataFrame等pandas对象的上下文中,使用标记的轴可以进一步泛化数组连接。尤其是还有许多需要考虑的事情:
- 如果对象在其他轴上的索引不同,是否应该将不同的元素组合在这些轴上,还是只使用共享的值(交集)?
- 连接的数据块是否需要在结果对象中被识别?
- “连接轴”是否包含需要保存的数据?
在许多情况下,DataFrame中的默认整数标签在连接期间最好丢弃。
pandas的concat函数提供了一种一致性的方式来解决以上问题。
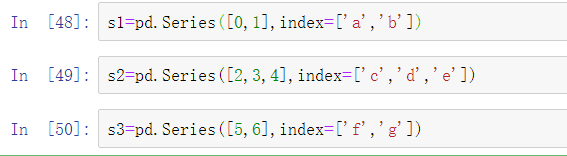
用列表中的这些对象调用concat方法会将值和索引粘在一起:
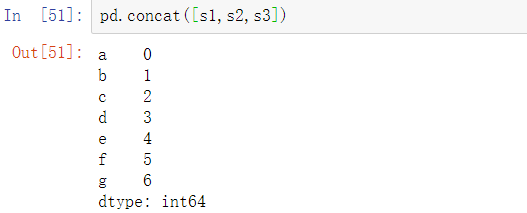
默认情况下,concat方法是沿着axis=0的轴向生效的,生成另一个Series。如果传递axis=1,返回的结果则是一个DataFrame(axis=1时是列):
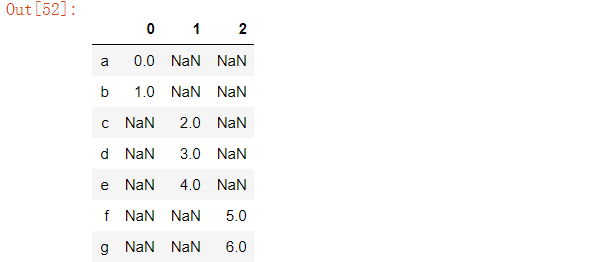
在这个案例中另一个轴向上并没有重叠,可以看到排序后的索引合集(’outer’ join外连接)。也可以传入join=’inner’:
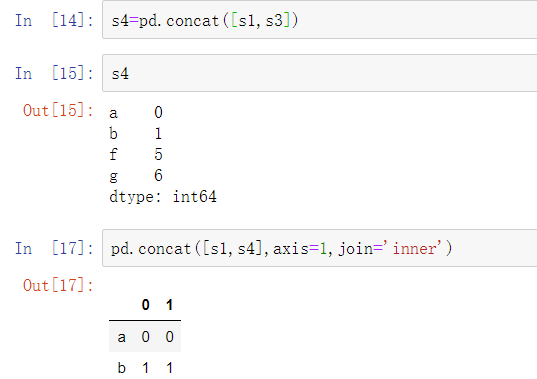
下表是concat函数的参数。

4 、联合重叠数据
还有另一个数据联合场景,既不是合并操作,也不是连接操作。可能有两个数据集,这两个数据集的索引全部或部分重叠。作为一个示例,考虑NumPy的where函数,这个函数可以进行面向数组的if-else等价操作:
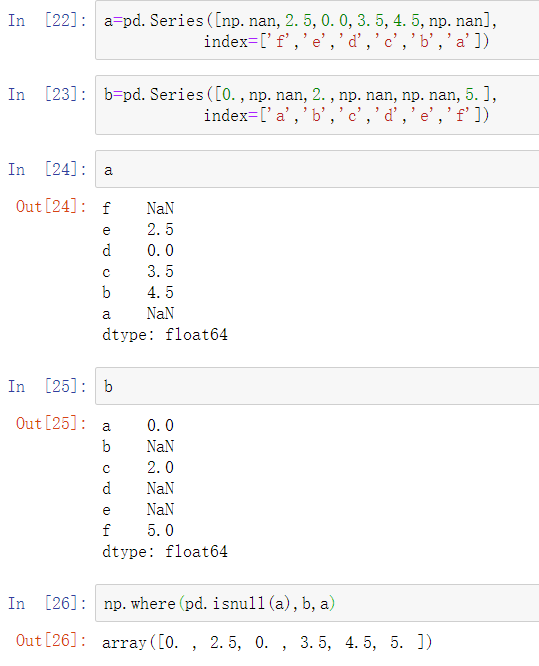
Series有一个combine_first方法,该方法可以等价于下面这种使用pandas常见数据对齐逻辑的轴向操作:
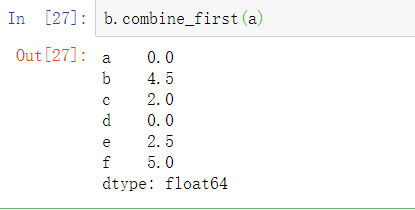
在DataFrame中,combine_first逐列做相同的操作,因此可以认为它是根据传入的对象来”修补“调用对象的缺失值: