- Python数据分析教程导航
- Python - 操作 MySQL 数据库
- Python 数据分析教程
- Python 数据分析
- NumPy数值计算基础
- Python ndarray
- Python NumPy矩阵
- 利用NumPy进行统计分析
- Python pandas基础
- Python pandas数据结构
- Python pandas基本功能
- Python pandas描述性统计
- Python 数据读取、存储与⽂件格式
- 文本格式数据的读写
- Python 二进制格式
- 数据清洗与准备
- Python 处理缺失值
- Python 数据转换
- 字符串操作
- 分层索引
- 联合与合并数据集
- Python 数据重塑和数据透视
- Python Matplotlib数据可视化基础
- Python 常用绘图库原理及示例
- Python 用pandas和seaborn绘图
- Python 可视化工具概览
- Python Pandas的分组聚合操作
- GroupBy机制
- 数据聚合
- Python 数据透视表与交叉表
- 时间序列
- 日期和时间数据的类型及工具
- 时间序列基础
- 日期范围、频率和移位
- 时区处理
- 时间区间和区间算术
- 重新采样与频率转换
- 移动窗口函数
- Python pandas分类数据
- 分类数据
- Python GroupBy进阶
- Python 方法链技术
- Python建模库介绍
- Python pandas与建模代码的结合
- statsmodels介绍
- Python 使用sklearn转换器处理数据
- Python 构建并评价聚类模型
- Python 构建并评价分类模型
- 构建并评价回归模型
- Python ndarray对象内幕
- 高阶数组操作
- Python 广播
- Python 高阶ufunc用法
- Python 排序
- Python 回归分析
- 回归分析的基本原理
- 一元线性回归
- 非线性回归
- 多项式回归
Python 使用sklearn转换器处理数据
使用sklearn转换器处理数据
sklearn 提供了 model_selection 模型选择模块、preprocessing 数据预处理模块与decompisition特征分解模块。通过这3个模块能够实现数据的预处理与模型构建前的数据标准化、二值化、数据集的分割、交叉验证和PCA降维等工作。
1、加载datasets模块中的数据集
sklearn 库的 datasets 模块集成了部分数据分析的经典数据集,可以使用这些数据集进行数据预处理、建模等操作,熟悉 sklearn 的数据处理流程和建模流程。datasets 模块常用数据集的加载函数与解释如表6-1所示。使用sklearn进行数据预处理会用到sklearn提供的统一接口——转换器(Transformer)。
datasets模块常用数据集加载函数及其解释如下表所示。

如果需要加载某个数据集,则可以将对应的函数赋值给某个变量。
加载后的数据集可以视为一个字典,几乎所有的sklearn数据集均可以使用data、target、feature_names、DESCR 分别获取数据集的数据、标签、特征名称和描述信息。
2、将数据集划分为训练集和测试集
在数据分析过程中,为了保证模型在实际系统中能够起到预期作用,一般需要将样本分成独立的3部分:训练集(train set)、验证集(validation set)和测试集(test set)。其中,训练集用于估计模型,验证集用于确定网络结构或者控制模型复杂程度的参数,而测试集则用于检验最优模型的性能。典型的划分方式是训练集占总样本的50%,而验证集和测试集各占25%。
当数据总量较少的时候,使用上面的方法将数据划分为3部分就不合适了。常用的方法是留少部分做测试集,然后对其余N个样本采用K折交叉验证法。其基本步骤是将样本打乱,然后均匀分成 K份,轮流选择其中 K−1份做训练,剩余的一份做验证,计算预测误差平方和,最后把K次的预测误差平方和的均值作为选择最优模型结构的依据。sklearn的model_selection模块提供了train_test_split函数,能够对数据集进行拆分,其使用格式如下。

train_test_split函数的常用参数及其说明如下表所示。

train_test_split函数分别将传入的数据划分为训练集和测试集。如果传入的是一组数据,那么生成的就是这一组数据随机划分后的训练集和测试集,总共两组。如果传入的是两组数据,则生成的训练集和测试集分别两组,总共4组。

3、使用sklearn转换器进行数据预处理与降维
为帮助用户实现大量的特征处理相关操作,sklearn把相关的功能封装为转换器。转换器主要包括3个方法:fit、transform和fit_transform。3种方法及其说明如下表所示。

目前,使用sklearn转换器能够实现对传入的NumPy数组进行标准化处理、归一化处理、二值化处理和PCA降维等操作。
在数据分析过程中,各类特征处理相关的操作都需要对训练集和测试集分开进行,需要将训练集的操作规则、权重系数等应用到测试集中。如果使用 pandas,则应用至测试集的过程相对烦琐,使用sklearn转换器可以解决这一困扰。
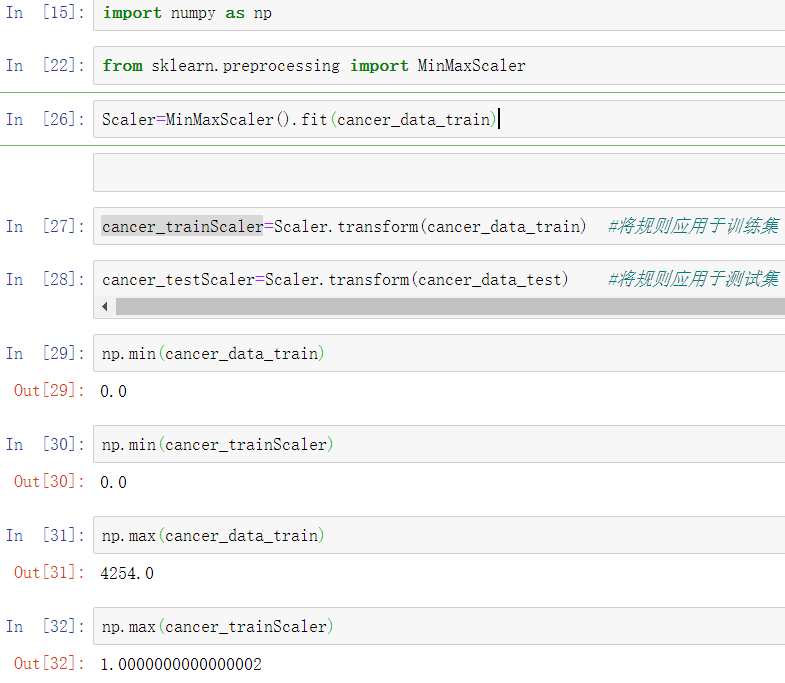
离差标准化之后的训练集数据的最小值、最大值的确限定在了[0,1]区间,同时由于测试集应用了训练集的离差标准化规则,数据超出了[0,1]的范围。这也侧面证明了此处应用了训练集的规则,如果两个数据集单独做离差标准化,或者两个数据集合并做离差标准化,根据公式则取值范围还是会限定在[0,1]区间。
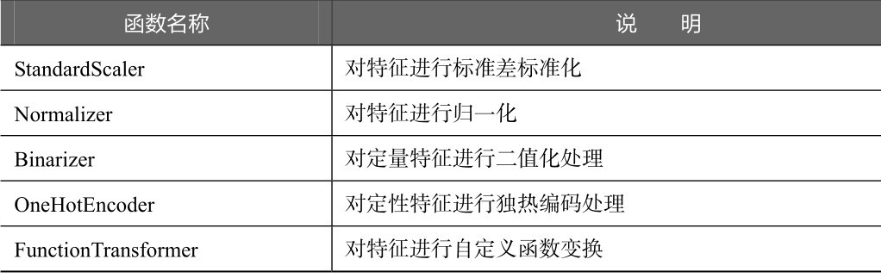
sklearn除了提供离差标准化函数MinMaxScaler外,还提供了一系列数据预处理函数,具体如下表所示。
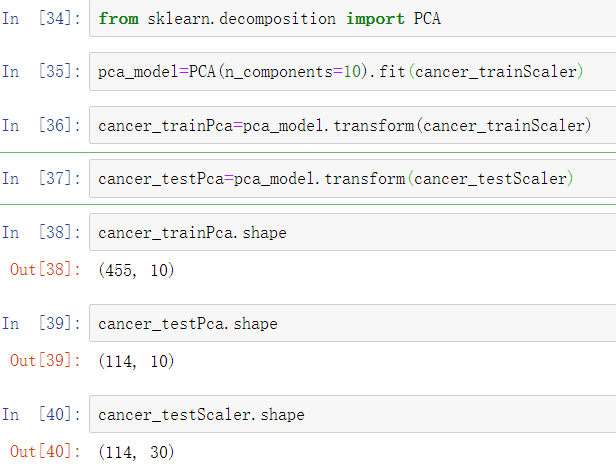
sklearn除了提供基本的特征变换函数外,还提供了降维算法、特征选择算法,这些算法的使用也是通过转换器的方式进行的。对breast_cancer数据集进行PCA降维,则特征维度为10。
PCA降维算法函数常用参数及其作用如下表所示。


