- Python数据分析教程导航
- Python - 操作 MySQL 数据库
- Python 数据分析教程
- Python 数据分析
- NumPy数值计算基础
- Python ndarray
- Python NumPy矩阵
- 利用NumPy进行统计分析
- Python pandas基础
- Python pandas数据结构
- Python pandas基本功能
- Python pandas描述性统计
- Python 数据读取、存储与⽂件格式
- 文本格式数据的读写
- Python 二进制格式
- 数据清洗与准备
- Python 处理缺失值
- Python 数据转换
- 字符串操作
- 分层索引
- 联合与合并数据集
- Python 数据重塑和数据透视
- Python Matplotlib数据可视化基础
- Python 常用绘图库原理及示例
- Python 用pandas和seaborn绘图
- Python 可视化工具概览
- Python Pandas的分组聚合操作
- GroupBy机制
- 数据聚合
- Python 数据透视表与交叉表
- 时间序列
- 日期和时间数据的类型及工具
- 时间序列基础
- 日期范围、频率和移位
- 时区处理
- 时间区间和区间算术
- 重新采样与频率转换
- 移动窗口函数
- Python pandas分类数据
- 分类数据
- Python GroupBy进阶
- Python 方法链技术
- Python建模库介绍
- Python pandas与建模代码的结合
- statsmodels介绍
- Python 使用sklearn转换器处理数据
- Python 构建并评价聚类模型
- Python 构建并评价分类模型
- 构建并评价回归模型
- Python ndarray对象内幕
- 高阶数组操作
- Python 广播
- Python 高阶ufunc用法
- Python 排序
- Python 回归分析
- 回归分析的基本原理
- 一元线性回归
- 非线性回归
- 多项式回归
Python 数据重塑和数据透视
重排列表格型数据有多种基础操作。这些操作被称为重塑或透视。
1、使用多层索引进行重塑
多层索引在DataFrame中提供了一种一致性方式用于重排列数据。以下是两个基础操作:
- statck(堆叠)该操作会“旋转”或将列中的数据透视到行。
- unstack(拆堆)该操作会将行中的数据透视到列。
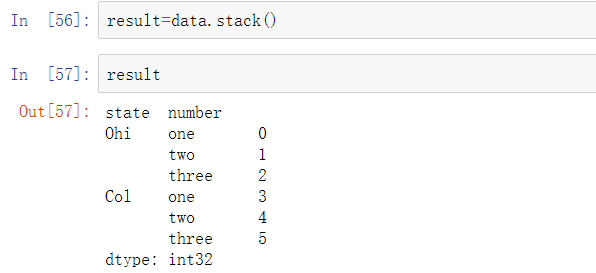
考虑一个带有字符串数组作为行和列索引的小型DataFrame:
在这份数据上使用stack方法会将列透视到行,产生一个新的Series:
从一个多层索引序列中,你可以使用unstack方法将数据重排列后放入一个DataFrame中:
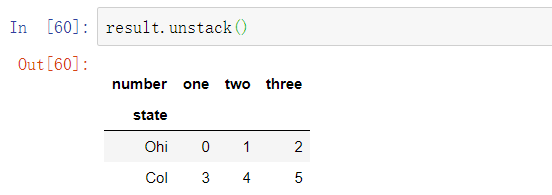
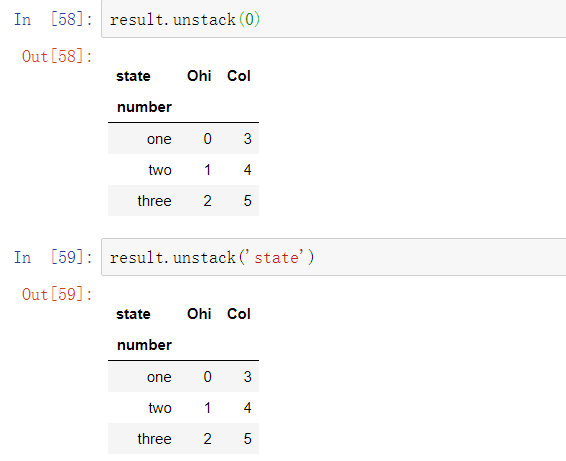
默认情况下,最内层是已拆堆的(与stack方法一样)。可以传入一个层级序号或名称来拆分一个不同的层级:
如果层级中的所有值并未包含于每个子分组中时,拆分可能会引入缺失值:
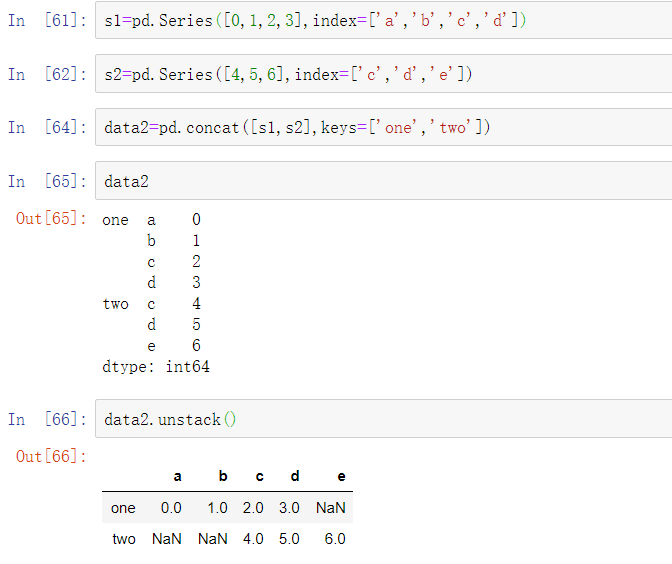
默认情况下,堆叠会过滤出缺失值,因此堆叠拆堆的操作是可逆的:
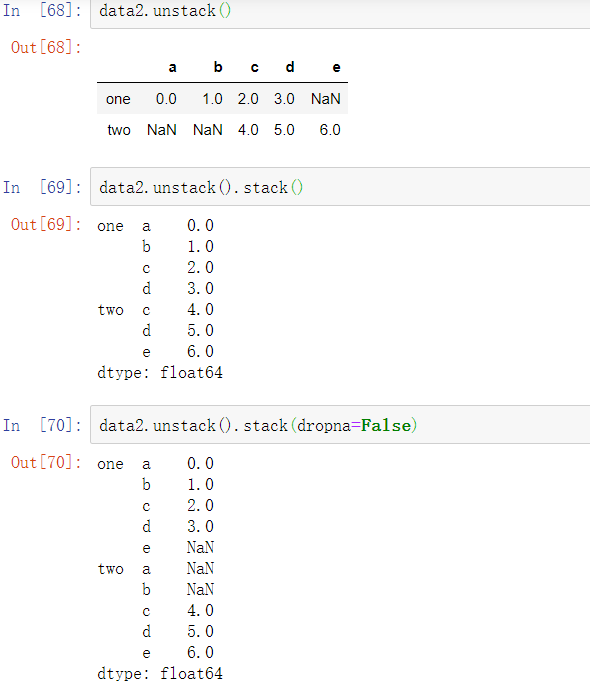
当在DataFrame中拆堆时,被拆堆的层级会变为结果中最低的层级:
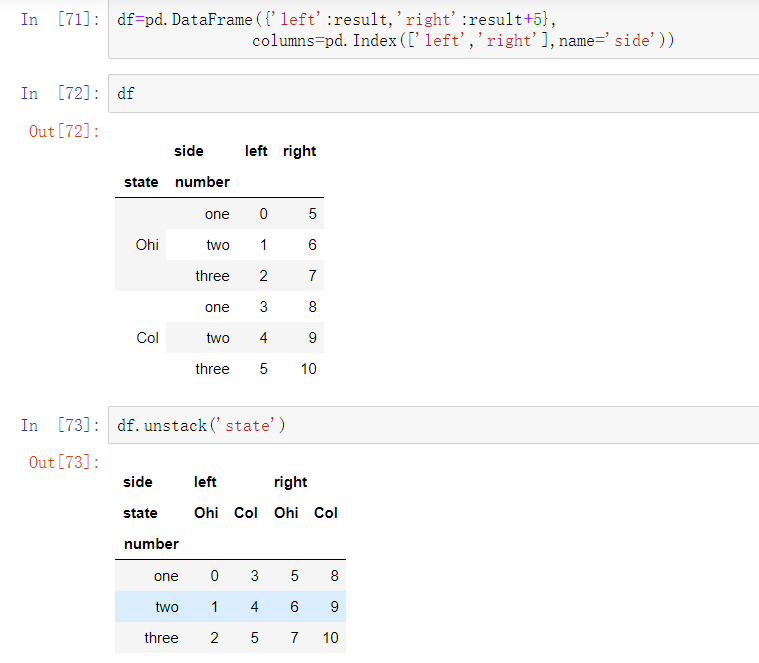
在调用stack方法时,我们可以指明需要堆叠的轴向名称:
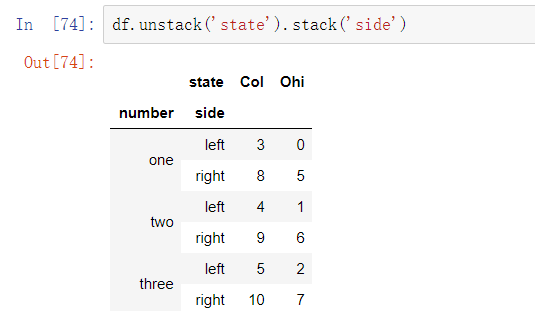
2、将“长”透视为“宽”
在数据库和CSV中存储多时间序列的方式就是所谓的长格式或堆叠格式。载入一些示例数据,然后做少量的时间序列规整和其他的数据清洗操作:
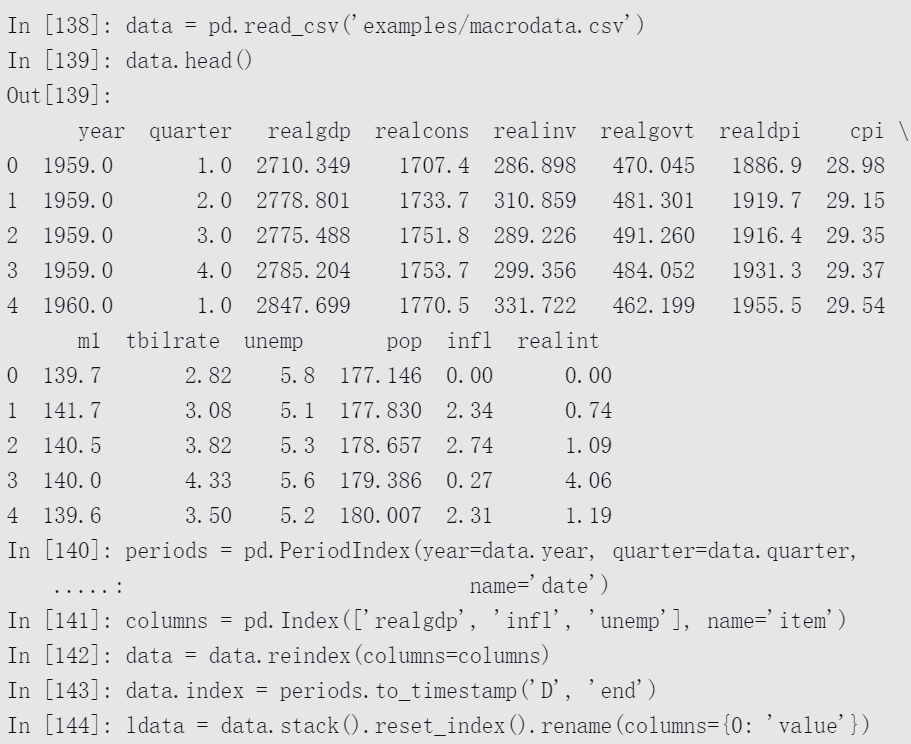
简单地说,PeriodIndex将year和quarter等列进行联合并生成了一种时间间隔类型:
现在,ldata看起来如下:
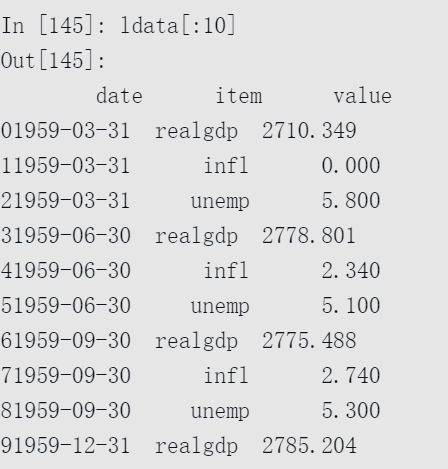
这种数据即所谓的多时间序列的长格式,或称为具有两个或更多个键的其他观测数据(这里的键是date和item)。表中的每一行表示一个时间点上的单个观测值。
3、将“宽”透视为“长”
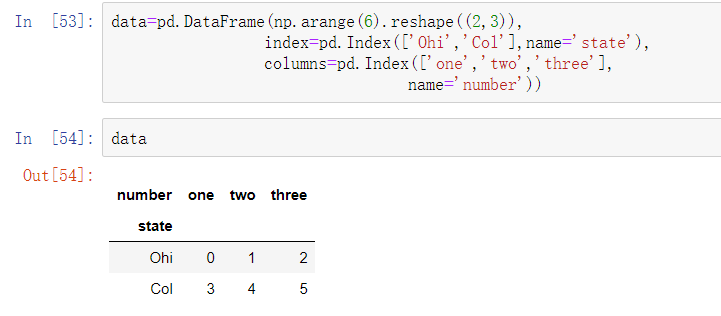
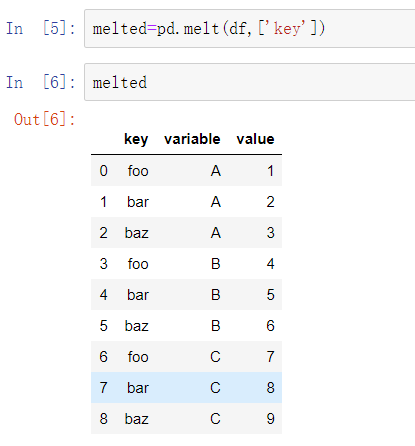
在DataFrame中,pivot方法的反操作是pandas.melt。与将一列变换为新的Data Frame中的多列不同,它将多列合并成一列,产生一个新的DataFrame,其长度比输入更长。
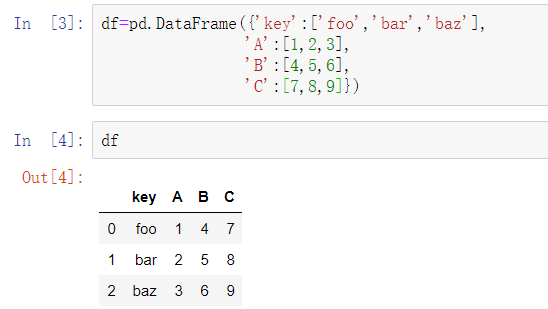
‘key’列可以作为分组指标,其他列均为数据值。当使用pandas.melt时,必须指明哪些列是分组指标(如果有的话)。
使用pivot方法,可以将数据重塑回原先的布局:
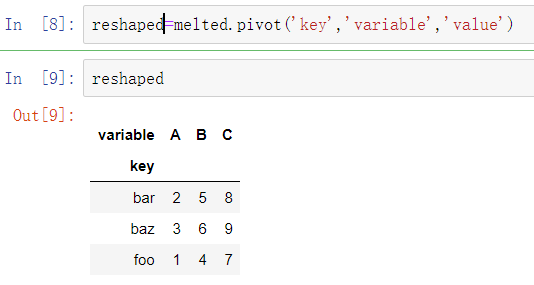
由于pivot的结果根据作为行标签的列生成了索引,使用reset_index来将数据回移一列:

也可以指定列的子集作为值列:

pandas.melt的使用也可以无须任何分组指标: