- Python数据分析教程导航
- Python - 操作 MySQL 数据库
- Python 数据分析教程
- Python 数据分析
- NumPy数值计算基础
- Python ndarray
- Python NumPy矩阵
- 利用NumPy进行统计分析
- Python pandas基础
- Python pandas数据结构
- Python pandas基本功能
- Python pandas描述性统计
- Python 数据读取、存储与⽂件格式
- 文本格式数据的读写
- Python 二进制格式
- 数据清洗与准备
- Python 处理缺失值
- Python 数据转换
- 字符串操作
- 分层索引
- 联合与合并数据集
- Python 数据重塑和数据透视
- Python Matplotlib数据可视化基础
- Python 常用绘图库原理及示例
- Python 用pandas和seaborn绘图
- Python 可视化工具概览
- Python Pandas的分组聚合操作
- GroupBy机制
- 数据聚合
- Python 数据透视表与交叉表
- 时间序列
- 日期和时间数据的类型及工具
- 时间序列基础
- 日期范围、频率和移位
- 时区处理
- 时间区间和区间算术
- 重新采样与频率转换
- 移动窗口函数
- Python pandas分类数据
- 分类数据
- Python GroupBy进阶
- Python 方法链技术
- Python建模库介绍
- Python pandas与建模代码的结合
- statsmodels介绍
- Python 使用sklearn转换器处理数据
- Python 构建并评价聚类模型
- Python 构建并评价分类模型
- 构建并评价回归模型
- Python ndarray对象内幕
- 高阶数组操作
- Python 广播
- Python 高阶ufunc用法
- Python 排序
- Python 回归分析
- 回归分析的基本原理
- 一元线性回归
- 非线性回归
- 多项式回归
Python 构建并评价分类模型
1 概述
分类是指构造一个分类模型,输入样本的特征值,输出对应的类别,将每个样本映射到预先定义好的类别。分类模型建立在已有类标记的数据集上,属于有监督学习。在实际应用场景中,分类算法被用于行为分析、物品识别、图像检测等。
本教程将介绍如何使用python实现分类模型。
2 使用sklearn估计器构建分类模型
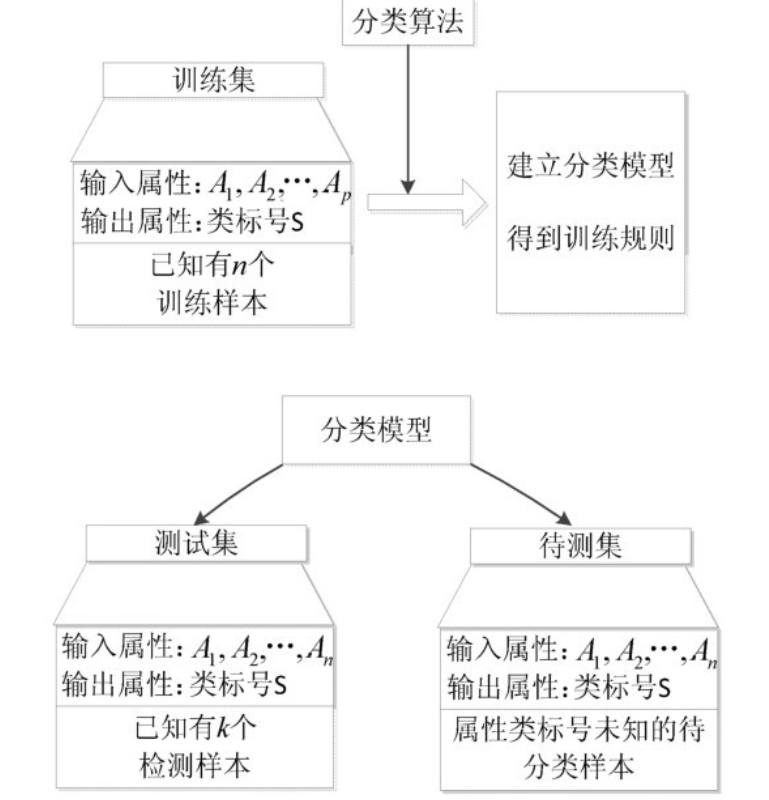
在python数据分析领域中,分类算法很多,其原理千差万别,有基于样本距离的最近邻算法、有基于特征信息熵的决策树、有基于 bagging 的随机森林、有基于 boosting 的梯度提升分类树,但其实现的过程相差不大,如下图所示。
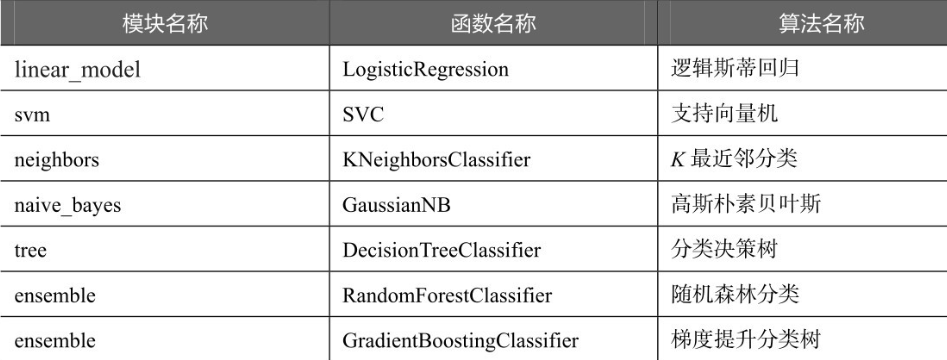
sklearn中提供的分类算法非常多,分别存在于不同的模块中。常用的分类算法如下表所示。
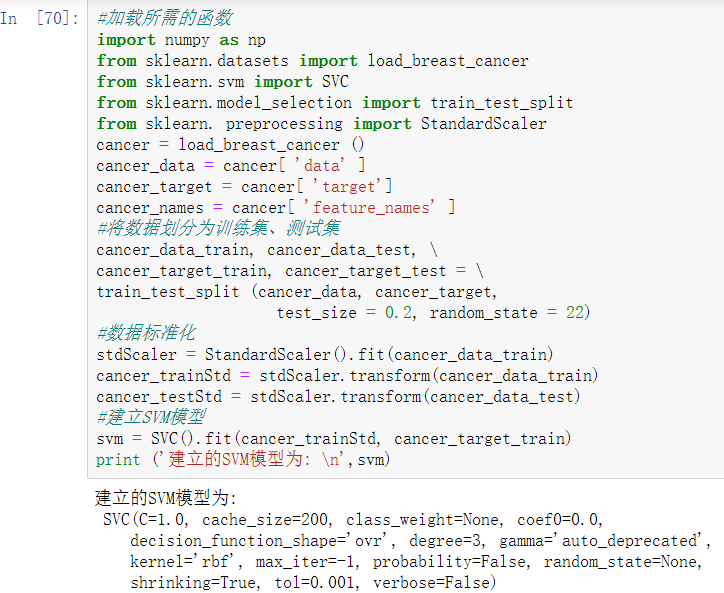
以breast_cancer数据为例,使用sklearn估计器构建支持向量机(SVM)模型。

将预测结果和真实结果做比对,求出预测对的结果和预测错的结果,并求出准确率。

SVM模型预测结果的准确率约为97.4%,只有3个测试样本识别错误,说明了整体模型效果比较理想。
3 评价分类模型
分类模型对测试集进行预测而得出的准确率并不能很好地反映模型的性能,为了有效判断一个预测模型的性能表现,需要结合真实值计算出精确率、召回率、F1 值和 Cohen’s Kappa系数等指标来衡量。
常规分类模型的评价方法如下表所示。
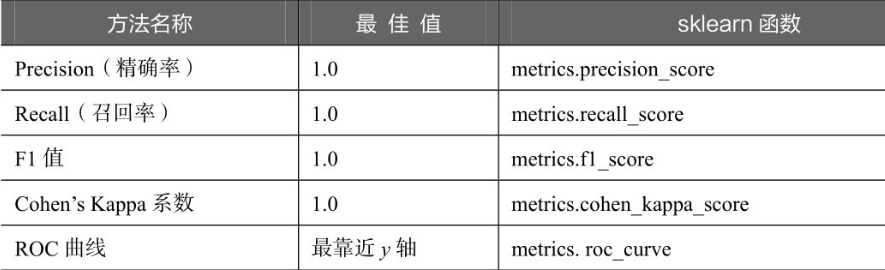
上表的分类模型评价方法中,前4种都是分值越高越好,其使用方法基本相同。
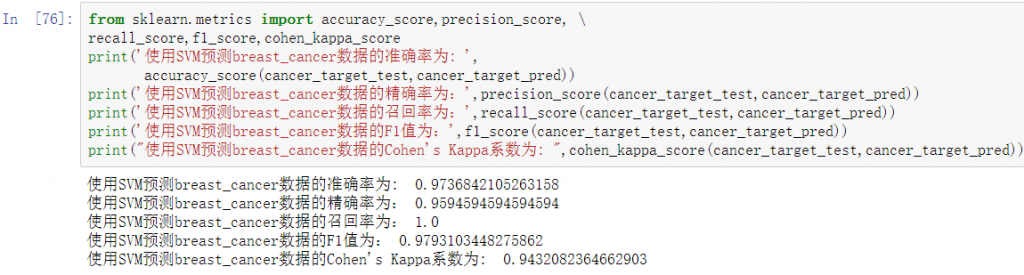
多种评价方法的得分十分接近1,说明了建立的SVM模型是有效的。
在python中,sklearn库的metrics模块除了提供了Precision等单一评价指标的函数外,还提供了一个能够输出分类模型评价报告的函数classification_report。
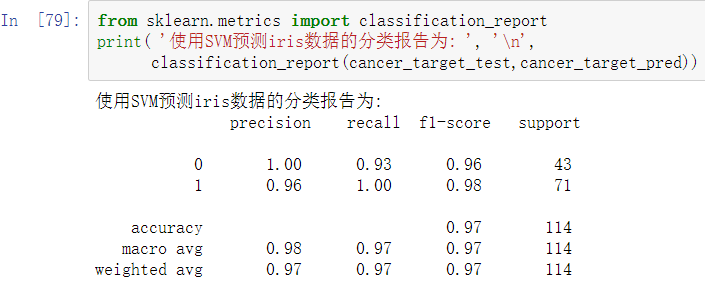
除了使用数值、表格形式评价分类模型的性能,还可通过绘制ROC曲线的方式来评价分类模型。
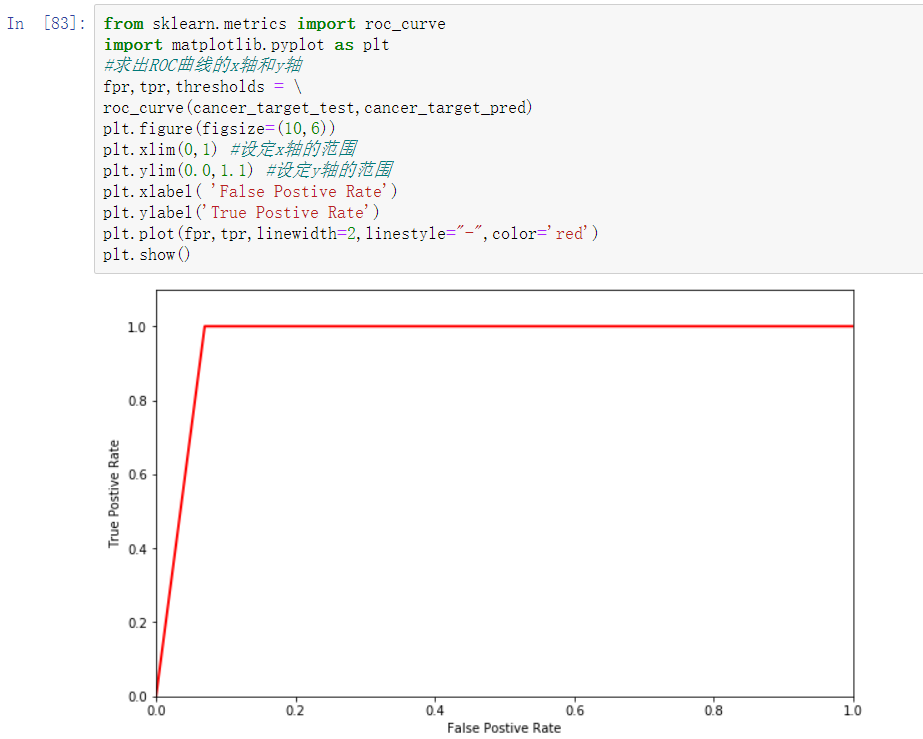
ROC曲线横纵坐标范围为[0,1],通常情况下,ROC曲线与x轴形成的面积越大,表示模型性能越好。当ROC曲线如代码6-21结果中的虚线所示时,表明了模型的计算结果基本都是随机得来的,在此情况下,模型起到的作用几乎为零。

