- Python数据分析教程导航
- Python - 操作 MySQL 数据库
- Python 数据分析教程
- Python 数据分析
- NumPy数值计算基础
- Python ndarray
- Python NumPy矩阵
- 利用NumPy进行统计分析
- Python pandas基础
- Python pandas数据结构
- Python pandas基本功能
- Python pandas描述性统计
- Python 数据读取、存储与⽂件格式
- 文本格式数据的读写
- Python 二进制格式
- 数据清洗与准备
- Python 处理缺失值
- Python 数据转换
- 字符串操作
- 分层索引
- 联合与合并数据集
- Python 数据重塑和数据透视
- Python Matplotlib数据可视化基础
- Python 常用绘图库原理及示例
- Python 用pandas和seaborn绘图
- Python 可视化工具概览
- Python Pandas的分组聚合操作
- GroupBy机制
- 数据聚合
- Python 数据透视表与交叉表
- 时间序列
- 日期和时间数据的类型及工具
- 时间序列基础
- 日期范围、频率和移位
- 时区处理
- 时间区间和区间算术
- 重新采样与频率转换
- 移动窗口函数
- Python pandas分类数据
- 分类数据
- Python GroupBy进阶
- Python 方法链技术
- Python建模库介绍
- Python pandas与建模代码的结合
- statsmodels介绍
- Python 使用sklearn转换器处理数据
- Python 构建并评价聚类模型
- Python 构建并评价分类模型
- 构建并评价回归模型
- Python ndarray对象内幕
- 高阶数组操作
- Python 广播
- Python 高阶ufunc用法
- Python 排序
- Python 回归分析
- 回归分析的基本原理
- 一元线性回归
- 非线性回归
- 多项式回归
Python pandas描述性统计
描述性统计的概述与计算
pandas对象装配了一个常用数学、统计学方法的集合。其中大部分属于归约或汇总统计的类别,这些方法从DataFrame的行或列中抽取一个Series或一系列值的单个值(如总和或平均值)。与NumPy数组中的类似方法相比,它们内建了处理缺失值的功能。
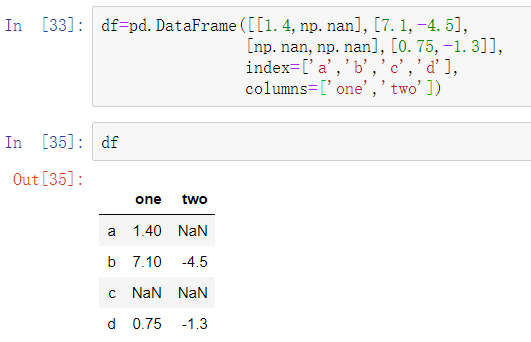
调用DataFrame的sum方法返回一个包含列上加和的Series:
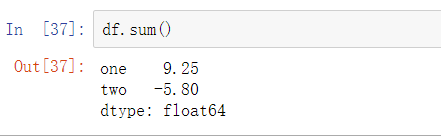
传入axis=’columns’或axis=1,则会将一行上各个列的值相加:
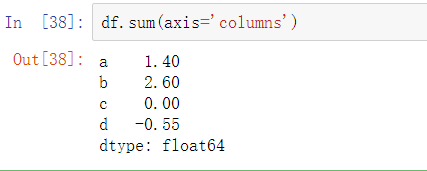
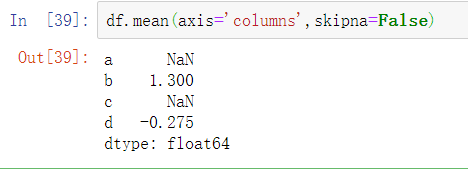
除非整个切片上(在本例中是行或列)都是NA,否则NA值是被自动排除的。可以通过禁用skipna来实现不排除NA值:
下表是归约方法的常用可选参数列表。

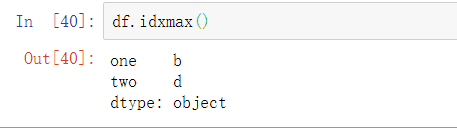
一些方法,比如idxmin和idxmax,返回的是间接统计信息,比如最小值或最大值的索引值:
除了归约方法外,有的方法是积累型方法:

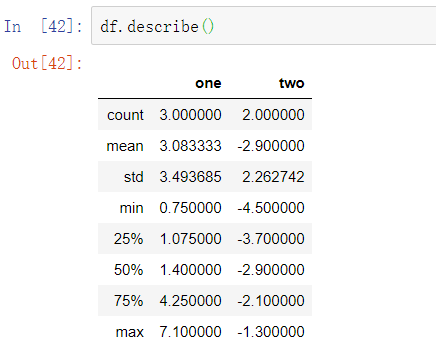
还有一类方法既不是归约型方法也不是积累型方法。describe就是其中之一,它一次性产生多个汇总统计:
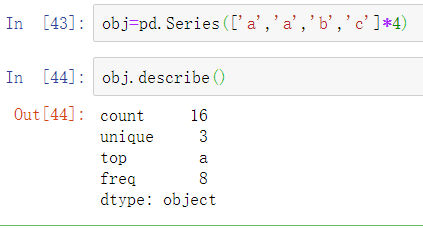
对于非数值型数据,describe产生另一种汇总统计:
下表是汇总统计及其相关方法的完整列表。
1、唯一值、计数和成员属性
一类相关的方法可以从一维Series包含的数值中提取信息。

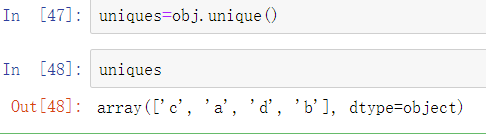
第一个函数是unique,它会给出Series中的唯一值:
唯一值并不一定按照排序好的顺序返回,但是如果需要的话可以进行排序(uniques. sort())。相应地,value_counts计算Series包含的值的个数:
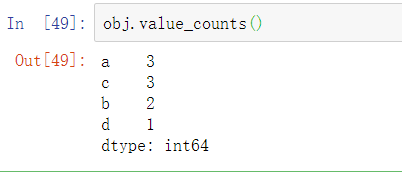
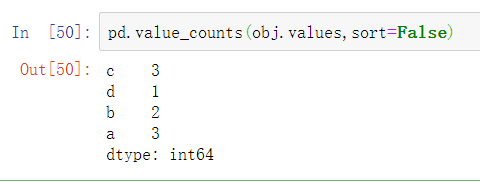
为了方便,返回的Series会按照数量降序排序。value_counts也是有效的pandas顶层方法,可以用于任意数组或序列:
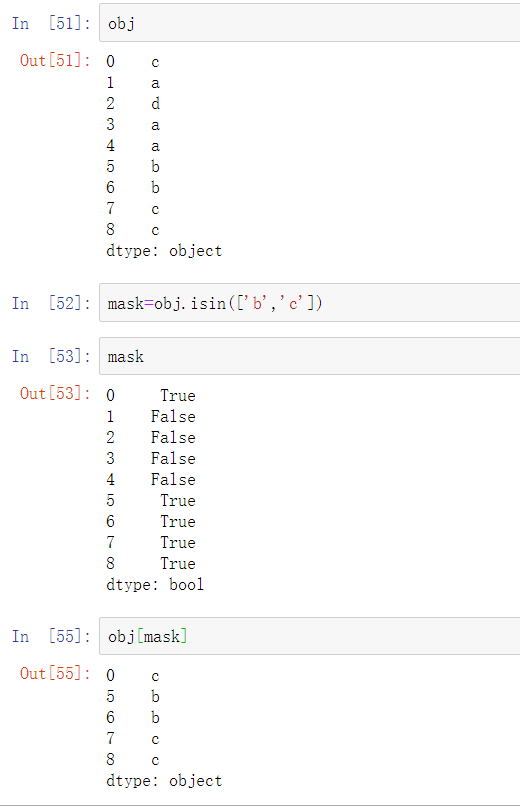
isin执行向量化的成员属性检查,还可以将数据集以Series或DataFrame一列的形式过滤为数据集的值子集:
与isin相关的Index.get_indexer方法,可以提供一个索引数组,这个索引数组可以将可能非唯一值数组转换为另一个唯一值数组:

下表是唯一值、计数和集合成员属性方法的参考。



评论区(0)