- Python数据分析教程导航
- Python - 操作 MySQL 数据库
- Python 数据分析教程
- Python 数据分析
- NumPy数值计算基础
- Python ndarray
- Python NumPy矩阵
- 利用NumPy进行统计分析
- Python pandas基础
- Python pandas数据结构
- Python pandas基本功能
- Python pandas描述性统计
- Python 数据读取、存储与⽂件格式
- 文本格式数据的读写
- Python 二进制格式
- 数据清洗与准备
- Python 处理缺失值
- Python 数据转换
- 字符串操作
- 分层索引
- 联合与合并数据集
- Python 数据重塑和数据透视
- Python Matplotlib数据可视化基础
- Python 常用绘图库原理及示例
- Python 用pandas和seaborn绘图
- Python 可视化工具概览
- Python Pandas的分组聚合操作
- GroupBy机制
- 数据聚合
- Python 数据透视表与交叉表
- 时间序列
- 日期和时间数据的类型及工具
- 时间序列基础
- 日期范围、频率和移位
- 时区处理
- 时间区间和区间算术
- 重新采样与频率转换
- 移动窗口函数
- Python pandas分类数据
- 分类数据
- Python GroupBy进阶
- Python 方法链技术
- Python建模库介绍
- Python pandas与建模代码的结合
- statsmodels介绍
- Python 使用sklearn转换器处理数据
- Python 构建并评价聚类模型
- Python 构建并评价分类模型
- 构建并评价回归模型
- Python ndarray对象内幕
- 高阶数组操作
- Python 广播
- Python 高阶ufunc用法
- Python 排序
- Python 回归分析
- 回归分析的基本原理
- 一元线性回归
- 非线性回归
- 多项式回归
分类数据
分类数据
本节会介绍pandas的Categorical类型。将展示在使用pandas进行某些操作时如何获得更好的性能和内存使用。还会介绍一些在统计和机器学习应用中使用分类数据的工具。
1、背景和目标
一个列经常会包含重复值,这些重复值是一个小型的不同值的集合。像unique和value_counts这样的函数,允许我们从一个数组中提取不同值并分别计算这些不同值的频率:
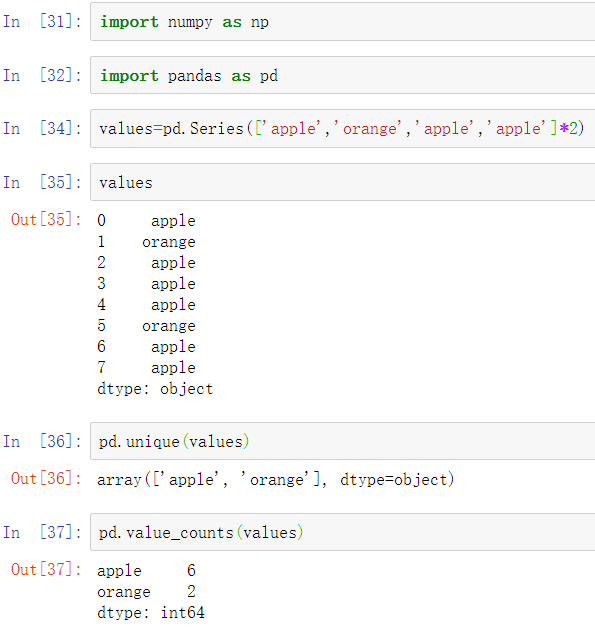
许多数据系统(用于数据入库、统计计算或其他用途)已经开发出专门的方法,用重复的值来表示数据,以便更有效地存储和计算。在数据入库的操作中,使用所谓的维度表是一种最佳实践,维度表包含了不同值,并将主要观测值存储为引用维度表的整数键:
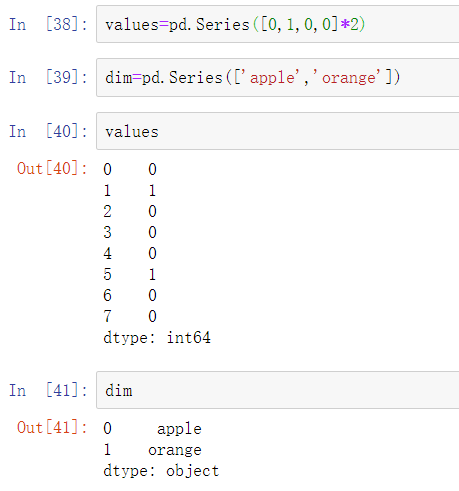
可以使用take方法来恢复原来的字符串Series:
这种按照整数展现的方式被称为分类或字典编码展现。不同值的数组可以被称为数据的类别、字典或层级。
在做数据分析时,分类展示会产生显著的性能提升。也可以在类别上进行转换同时不改变代码。以下是一些相对低开销的转换示例:
- 重命名类别
- 在不改变已有的类别顺序的情况下添加一个新的类别
2、pandas中的Categorical类型
pandas拥有特殊的Categorical类型,用于承载基于整数的类别展示或编码的数据。
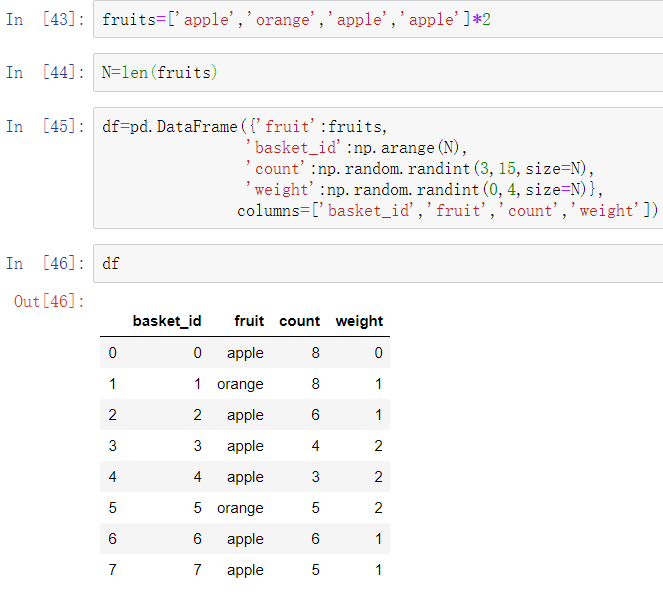
这里,df[‘fruit’]是一个Python字符串对象组成的数组。可以通过调用函数将它转换为Categorical对象:
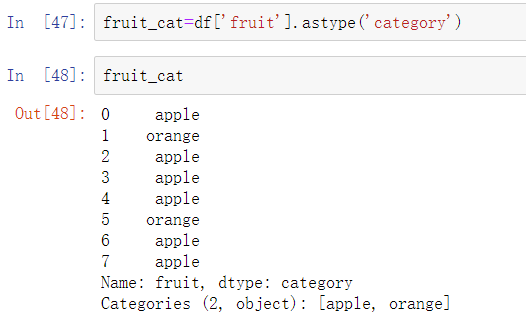
fruit_cat的值并不是NumPy数组,而是pandas.Categorical的实例:
Categorical对象拥有categories和codes属性:

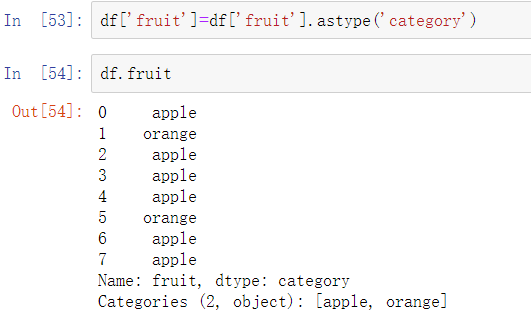
可以通过分配已转换的结果将DataFrame的一列转换为Categorical对象:
需要注意,分类数据可以不是字符串,尽管我举的例子都是字符串例子。一个分类数组可以包含任一不可变的值类型。
3、使用Categorical对象进行计算
在pandas中使用Categorical与非编码版本相比(例如字符串数组)整体上是一致的。pandas中的某些部分,比如groupby函数,在与Categorical对象协同工作时性能更好。还有一些函数可以利用ordered标识。
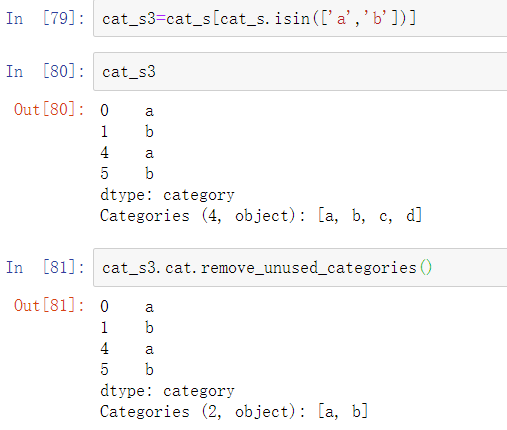
考虑一些随机数字数据,并使用pandas.qcut分箱函数。结果会返回pandas.Categorical:
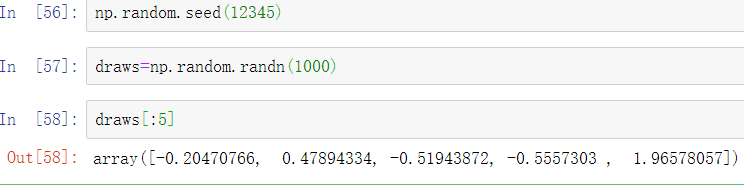
我们计算上面数据的四分位分箱,并提取一些统计值:

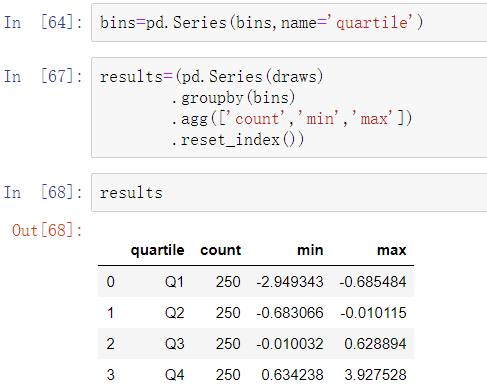
虽然样本的四分位数有用,但是在生成一份报告时,四分位数就没有四分位数名称有用了。

被标记的bins分类数据并不包含数据中箱体边界的相关信息,因此可以使用groupby来提取一些汇总统计值:
3.1 使用分类获得更高性能
如果在特定的数据集上做了大量的分析,将数据转换为分类数据可以产生大幅的性能提升。DateFrame中一列的分类版本通常也会明显使用更少内存。

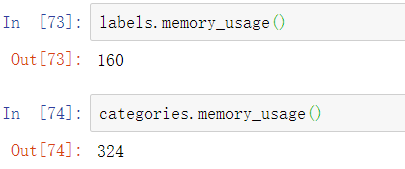
现在将labels转换为Categorical对象:

现在我们注意到labels比categories使用了明显更多的内存:
4、分类方法
Series包含的分类数据拥有一些特殊方法,这些方法类似于Series.str的特殊字符串方法。这些方法提供了快捷访问类别和代码的方式。考虑下面的Series:
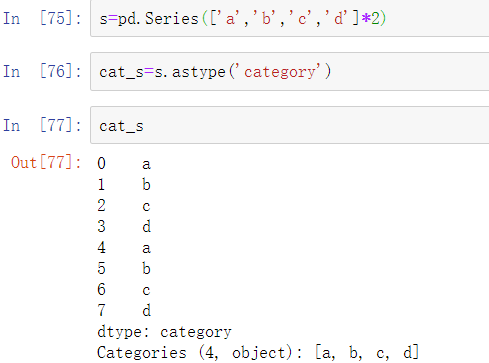
特殊属性cat提供了对分类方法的访问:
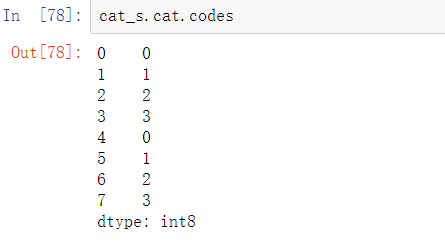
在大型数据集中,分类数据经常被用于节省内存和更高性能的便捷工具。在过滤了一个大型DataFrame或Series之后,很多类别将不会出现在数据中。为了帮助解决这个问题,可以使用remove_unused_categories方法来去除未观察到的类别:
下表是可用的分类方法列表。

4.1 创建用于建模的虚拟变量
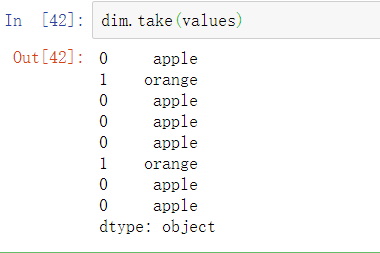
当使用统计数据或机器学习工具时,通常会将分类数据转换为虚拟变量,也称为one-hot编码。这会产生一个DataFrame,每个不同的类别都是它的一列。这些列包含一个特定类别的出现次数,否则为0。

pandas.get_dummies函数将一维的分类数据转换为一个包含虚拟变量的DataFrame: