- Python数据分析教程导航
- Python - 操作 MySQL 数据库
- Python 数据分析教程
- Python 数据分析
- NumPy数值计算基础
- Python ndarray
- Python NumPy矩阵
- 利用NumPy进行统计分析
- Python pandas基础
- Python pandas数据结构
- Python pandas基本功能
- Python pandas描述性统计
- Python 数据读取、存储与⽂件格式
- 文本格式数据的读写
- Python 二进制格式
- 数据清洗与准备
- Python 处理缺失值
- Python 数据转换
- 字符串操作
- 分层索引
- 联合与合并数据集
- Python 数据重塑和数据透视
- Python Matplotlib数据可视化基础
- Python 常用绘图库原理及示例
- Python 用pandas和seaborn绘图
- Python 可视化工具概览
- Python Pandas的分组聚合操作
- GroupBy机制
- 数据聚合
- Python 数据透视表与交叉表
- 时间序列
- 日期和时间数据的类型及工具
- 时间序列基础
- 日期范围、频率和移位
- 时区处理
- 时间区间和区间算术
- 重新采样与频率转换
- 移动窗口函数
- Python pandas分类数据
- 分类数据
- Python GroupBy进阶
- Python 方法链技术
- Python建模库介绍
- Python pandas与建模代码的结合
- statsmodels介绍
- Python 使用sklearn转换器处理数据
- Python 构建并评价聚类模型
- Python 构建并评价分类模型
- 构建并评价回归模型
- Python ndarray对象内幕
- 高阶数组操作
- Python 广播
- Python 高阶ufunc用法
- Python 排序
- Python 回归分析
- 回归分析的基本原理
- 一元线性回归
- 非线性回归
- 多项式回归
Python pandas数据结构
pandas数据结构介绍
为了入门pandas,需要熟悉两个常用的工具数据结构:Series和DataFrame。尽管他们并不能解决所有的问题,但它们为大多数应用提供了一个有效、易用的基础。
1、Series
Series是一种一维的数组型对象,它包含了一个值序列(与NumPy中的类型相似),并且包含了数据标签,称为索引(index)。最简单的序列可以仅仅由一个数组形成:
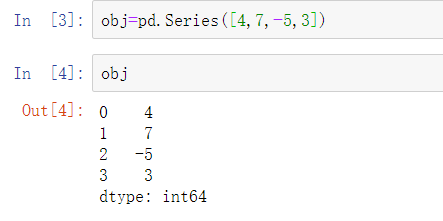
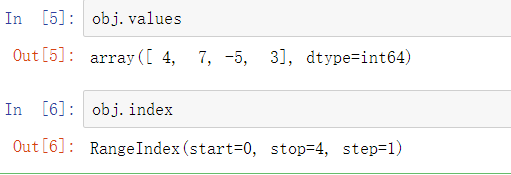
交互式环境中Series的字符串表示,索引在左边,值在右边。由于我们不为数据指定索引,默认生成的索引是从0到N-1(N是数据的长度)。可以通过values属性和index属性分别获得Series对象的值和索引:
通常需要创建一个索引序列,用标签标识每个数据点:
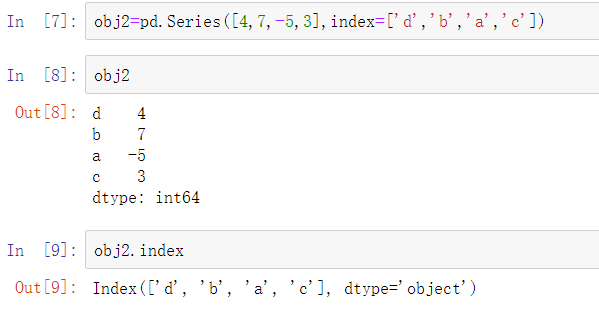
与NumPy的数组相比,你可以在从数据中选择数据的时候使用标签来进行索引:
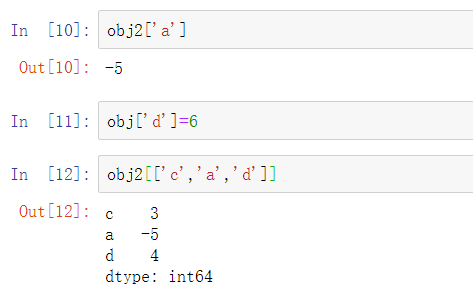
上面的例子中,[‘c’,’a’,’d’]包含的不是数字而是字符串,作为索引列表。
从另一个角度考虑Series,可以认为它是一个长度固定且有序的字典,因为它将索引值和数据值按位置配对。在你可能会使用字典的上下文中,也可以使用Series:
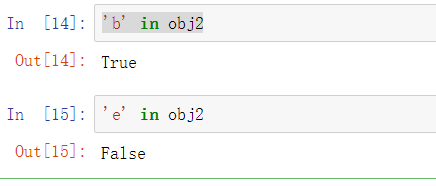
如果已经有数据包含在Python字典中,你可以使用字典生成一个Series:
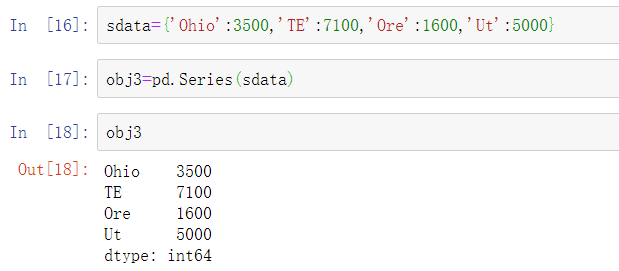
当把字典传递给Series构造函数时,产生的Series的索引将是排序好的字典键。可以将字典键按照你所想要的顺序传递给构造函数,从而使生成的Series的索引顺序符合预期:
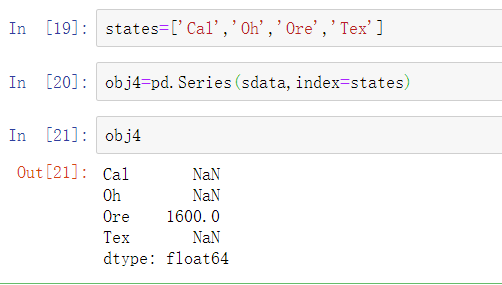
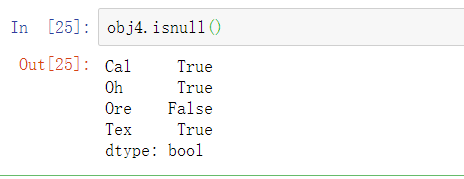
使用术语“缺失”或“NA”来表示缺失数据。pandas中使用isnull和notnull函数来检查缺失数据:
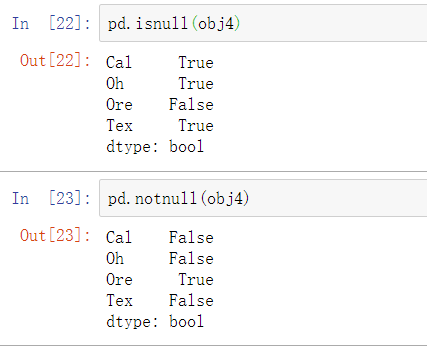
isnull和notnull也是Series的实例方法:
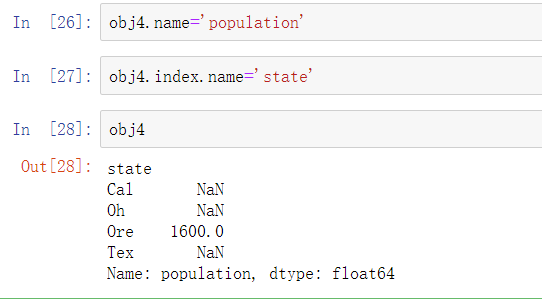
Series对象自身和其索引都有name属性,这个特性与pandas其他重要功能集成在一起:
2、DataFrame
DataFrame表示的是矩阵的数据表,它包含已排序的列集合,每一列可以是不同的值类型(数值、字符串、布尔值等)。DataFrame既有行索引也有列索引,它可以被视为一个共享相同索引的Series的字典。在DataFrame中,数据被存储为一个以上的二维块,而不是列表、字典或其他一维数组的集合。
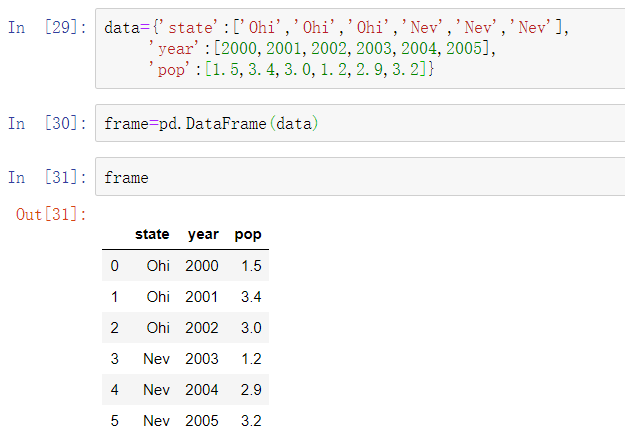
有多种方式可以构建DataFrame,其中最常用的方式是利用包含等长度列表或NumPy数组的字典来形成DataFrame:
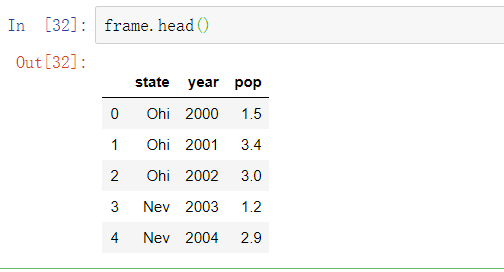
对于大型DataFrame, head方法将会只选出头部的五行:
如果你指定了列的顺序,DataFrame的列将会按照指定顺序排列:
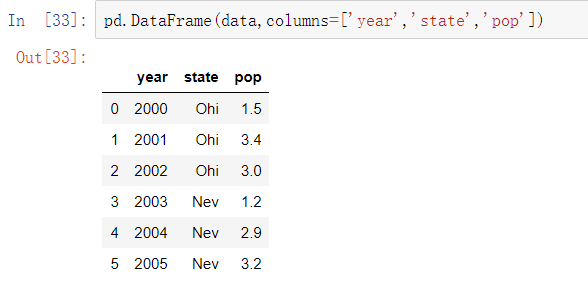
DataFrame中的一列,可以按字典型标记或属性那样检索为Series:
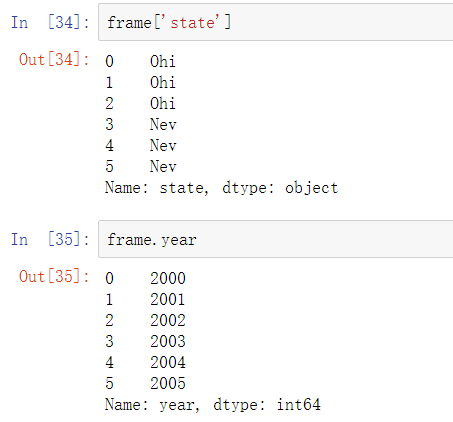
frame2[colunm]对于任意列名均有效,但是frame2.column只在列名是有效的Python变量名时有效。
行也可以通过位置或特殊属性loc进行选取:
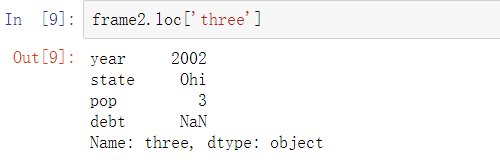
列的引用是可以修改的。例如,空的’debt’列可以赋值为标量值或值数组:
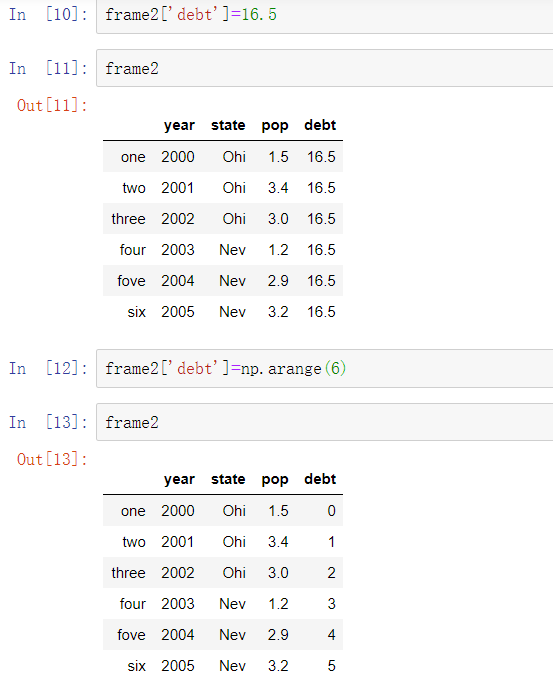
当你将列表或数组赋值给一个列时,值的长度必须和DataFrame的长度相匹配。如果你将Series赋值给一列时,Series的索引将会按照DataFrame的索引重新排列,并在空缺的地方填充缺失值:
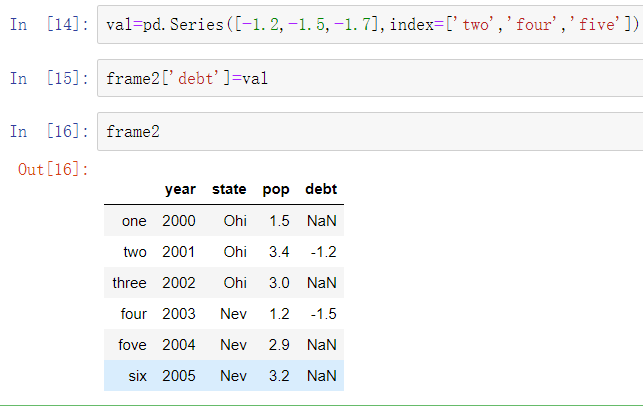
如果被赋值的列并不存在,则会生成一个新的列。del关键字可以像在字典中那样对DataFrame删除列。
注意:从DataFrame中选取的列是数据的视图,而不是拷贝。因此,对Series的修改会映射到DataFrame中。如果需要复制,则应当显式地使用Series的copy方法。
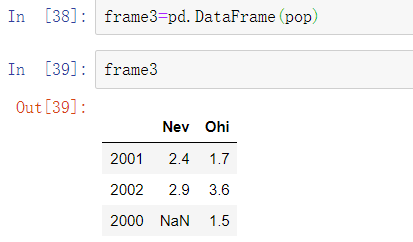
另一种常用的数据形式是包含字典的嵌套字典:

如果嵌套字典被赋值给DataFrame, pandas会将字典的键作为列,将内部字典的键作为行索引:
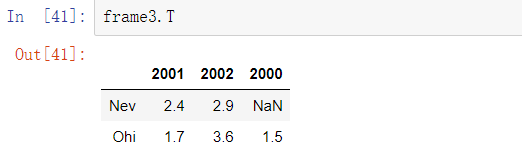
可以将使用类似NumPy的语法对DataFrame进行转置操作(调换行和列):
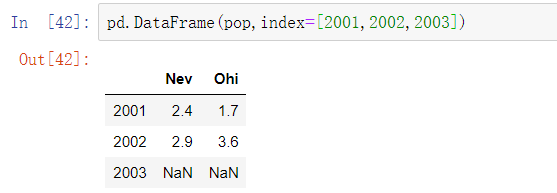
内部字典的键被联合、排序后形成了结果的索引。如果已经显式指明索引的话,内部字典的键将不会被排序:
如果DataFrame的索引和列拥有name属性,则这些name属性也会被显示:
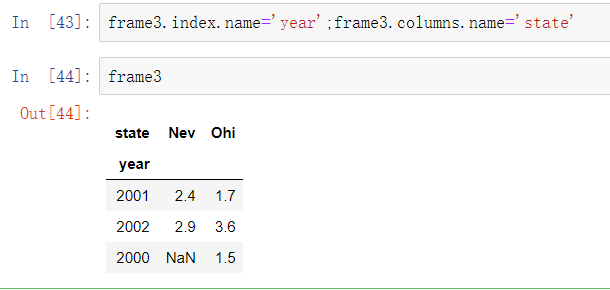
和Series类似,DataFrame的values属性会将包含在DataFrame中的数据以二维ndarray的形式返回:

3 、索引对象
pandas中的索引对象是用于存储轴标签和其他元数据的(例如轴名称或标签)。在构造Series或DataFrame时,你所使用的任意数组或标签序列都可以在内部转换为索引对象:

索引对象是不可变的,因此用户是无法修改索引对象的。
不变性使得在多种数据结构中分享索引对象更为安全:
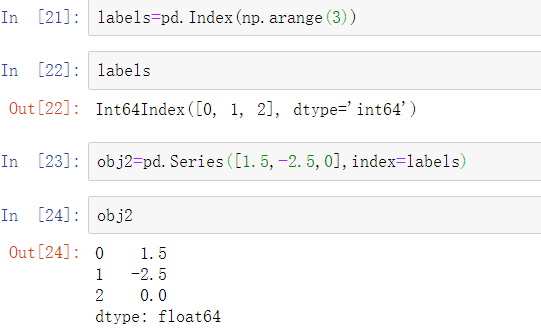
除了类似数组,索引对象也像一个固定大小的集合:
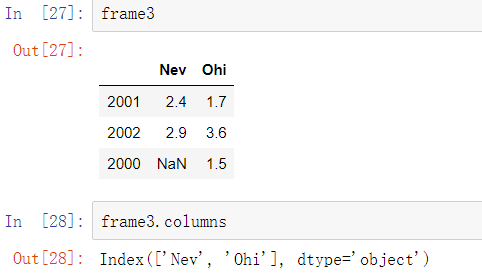
根据重复标签进行筛选,会选取所有重复标签对应的数据。每个索引都有一些集合逻辑的方法和属性,这些方法和属性解决了关于它所包含的数据的其他常见问题。下表总结了这些方法和属性中常用的一部分。



评论区(0)