- Python数据分析教程导航
- Python - 操作 MySQL 数据库
- Python 数据分析教程
- Python 数据分析
- NumPy数值计算基础
- Python ndarray
- Python NumPy矩阵
- 利用NumPy进行统计分析
- Python pandas基础
- Python pandas数据结构
- Python pandas基本功能
- Python pandas描述性统计
- Python 数据读取、存储与⽂件格式
- 文本格式数据的读写
- Python 二进制格式
- 数据清洗与准备
- Python 处理缺失值
- Python 数据转换
- 字符串操作
- 分层索引
- 联合与合并数据集
- Python 数据重塑和数据透视
- Python Matplotlib数据可视化基础
- Python 常用绘图库原理及示例
- Python 用pandas和seaborn绘图
- Python 可视化工具概览
- Python Pandas的分组聚合操作
- GroupBy机制
- 数据聚合
- Python 数据透视表与交叉表
- 时间序列
- 日期和时间数据的类型及工具
- 时间序列基础
- 日期范围、频率和移位
- 时区处理
- 时间区间和区间算术
- 重新采样与频率转换
- 移动窗口函数
- Python pandas分类数据
- 分类数据
- Python GroupBy进阶
- Python 方法链技术
- Python建模库介绍
- Python pandas与建模代码的结合
- statsmodels介绍
- Python 使用sklearn转换器处理数据
- Python 构建并评价聚类模型
- Python 构建并评价分类模型
- 构建并评价回归模型
- Python ndarray对象内幕
- 高阶数组操作
- Python 广播
- Python 高阶ufunc用法
- Python 排序
- Python 回归分析
- 回归分析的基本原理
- 一元线性回归
- 非线性回归
- 多项式回归
Python ndarray对象内幕
ndarray对象内幕
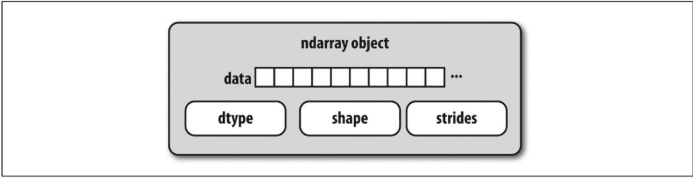
NumPy的ndarray提供了一种方法将一组同构数据(连续的或跨步的)解释为多维数组对象。数据类型或dtype决定数据如何被解释为浮点数、整数、布尔值或我们正在查看的任何其他类型。
让ndarray如此灵活的部分原因是每个数组对象都是一个数据块的分步视图。可能会想知道数组视图arr[::2, ::-1]如何做到不复制任何数据。原因是ndarray不仅仅是一块内存和一个dtype,它还具有“跨步”信息,使数组能够以不同的步长在内存中移动。更准确地说,ndarray内部包含以下内容:
- 指向数据的指针——即RAM中或内存映射文件中的数据块
- 数据类型或dtype,描述数组中固定大小的值单元格
- 表示数组形状(shape)的元组
- 步长元组,表示要“步进”的字节数的整数以便沿维度推进一个元素
下图是简单的ndarray内部构造。
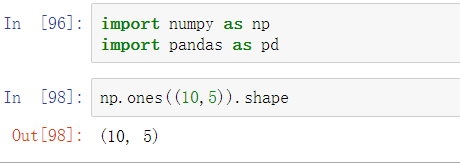
一个10×5的数组,其shape为(10, 5):
一个典型的(C阶)3×4×5 float64值(8字节)的数组具有跨度(160,40,8)(了解跨度可能是有用的,因为通常特定轴上的跨度越大,沿着该轴执行计算的代价越高):

虽然一般的NumPy用户很少会对数组跨度(strides)感兴趣,但它们是构建“零复制”数组视图的关键因素。跨度甚至可以是负的,这使得数组能够穿过内存“向后”移动(例如,在诸如obj[::-1]或obj[:, ::-1]的切片中就是这种情况)。
1、NumPy dtype层次结构
可能会需要写代码检查数组是否包含整数、浮点数、字符串或Python对象。由于浮点数有多种类型(float16到float128),因此检查dtype是否在类型列表中会非常麻烦。幸运的是,dtype有超类,如np.integer和np.floating,它们可以和np.issubdtype函数一起使用:

可以通过调用类型的mro方法来查看特定dtype的所有父类:
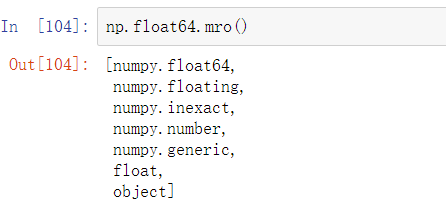
可以得到:

下图是dtype的层次结构父类-子类关系图。
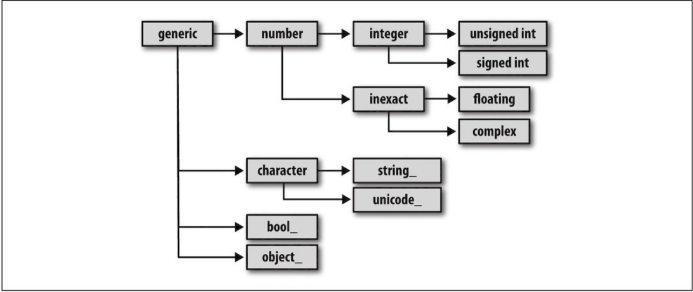
2、结构化和记录数组
ndarray是一个同构数据的容器。也就是说,它表示一个内存块,其中每个元素占用相同数量的字节,由dtype确定。表面上,ndarray的这种特性不允许你使用它表示异构的数据或表格型数据。结构化数组是一个ndarray,其中每个元素可以被认为代表C中的struct(因此是“结构化”的名称),或者是SQL表中具有多个命名字段的行:

一种典型的方式是使用(field_name, field_data_type)作为元组的列表。现在,数组的元素是元组对象,其元素可以像字典一样访问:
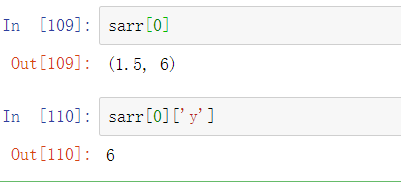
字段名称存储在dtype.names属性中。当访问结构化数组中的字段时,将返回数据的分步视图,因此不会复制任何内容:
2.1 嵌套dtype和多维字段
当指定结构化的dtype时,可以另外传递一个形状(以int或元组的形式):

在这种情况下,x字段引用的是每条记录中长度为3的数组:
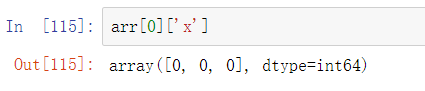
很方便地,访问arr[‘x’]然后返回一个二维数组,而不是像之前的例子那样返回一个一维数组:
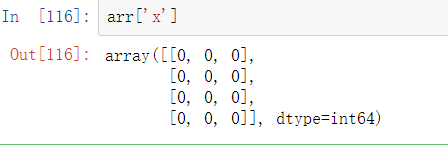
这使你可以将更复杂的嵌套结构表示为数组中的单个内存块。也可以嵌套dtype来创建更复杂的结构。

2.2 为什么要使用结构化数组
与pandas的DataFrame相比,NumPy结构化数组是一个相对底层的工具。结构化数组提供了一种将内存块解释为具有任意复杂嵌套列的表格结构的方法。由于数组中的每个元素都在内存中表示为固定数量的字节,因此结构化数组提供了读/写磁盘(包括内存映射)数据,以及在网络上传输数据和其他此类用途的非常快速有效的方法。
作为结构化数组的另一种常见用途,将数据文件编写为固定长度的记录字节流是将C和C ++代码中的数据序列化的常用方法,这在业界传统系统中很常见。只要知道文件的格式(每个记录的大小以及每个元素的顺序、字节大小和数据类型),就可以用np.fromfile将数据读入内存。

