- OLAP工具 - Druid导航
- Apache Druid 简介
- Apache Druid 下载安装
- Apache Druid 启动
- Apache Druid 集群部署
- Apache Druid 数据格式
- Druid入门指南 加载本地文件
- Druid入门指南 查询数据教程
- Druid入门指南 加载Kafka数据
- Druid入门指南 加载Hadoop数据
- Druid入门指南 Rollup操作
- Druid入门指南 配置数据保留规则
- Druid入门指南 数据更新
- Druid入门指南 合并段文件
- Druid入门指南 删除数据
- Druid入门指南 摄入配置规范
- Druid入门指南 数据过滤与转换
- Druid入门指南 Kerberized HDFS存储
- Druid架构设计 整体设计
- Druid架构设计 段设计
- Druid架构设计 进程与服务
- Druid架构设计 深度存储与本地挂载
- Druid架构设计 元数据存储
- Druid架构设计 Zookeeper
- Druid数据摄取 概述
- Druid数据摄取 数据格式
- Druid数据摄取 Schema设计
- Druid数据摄取 数据管理
Druid入门指南 配置数据保留规则
quickstart/tutorial/retention-index.jsonretention-tutorial
bin/post-index-task --file quickstart/tutorial/retention-index.json --url http://localhost:8081
http://localhost:8888/unified-console.html#datasources
可用数据源保留规则摘要

retention-tutorial
注意_default_tier_default_tier
retention-tutorial
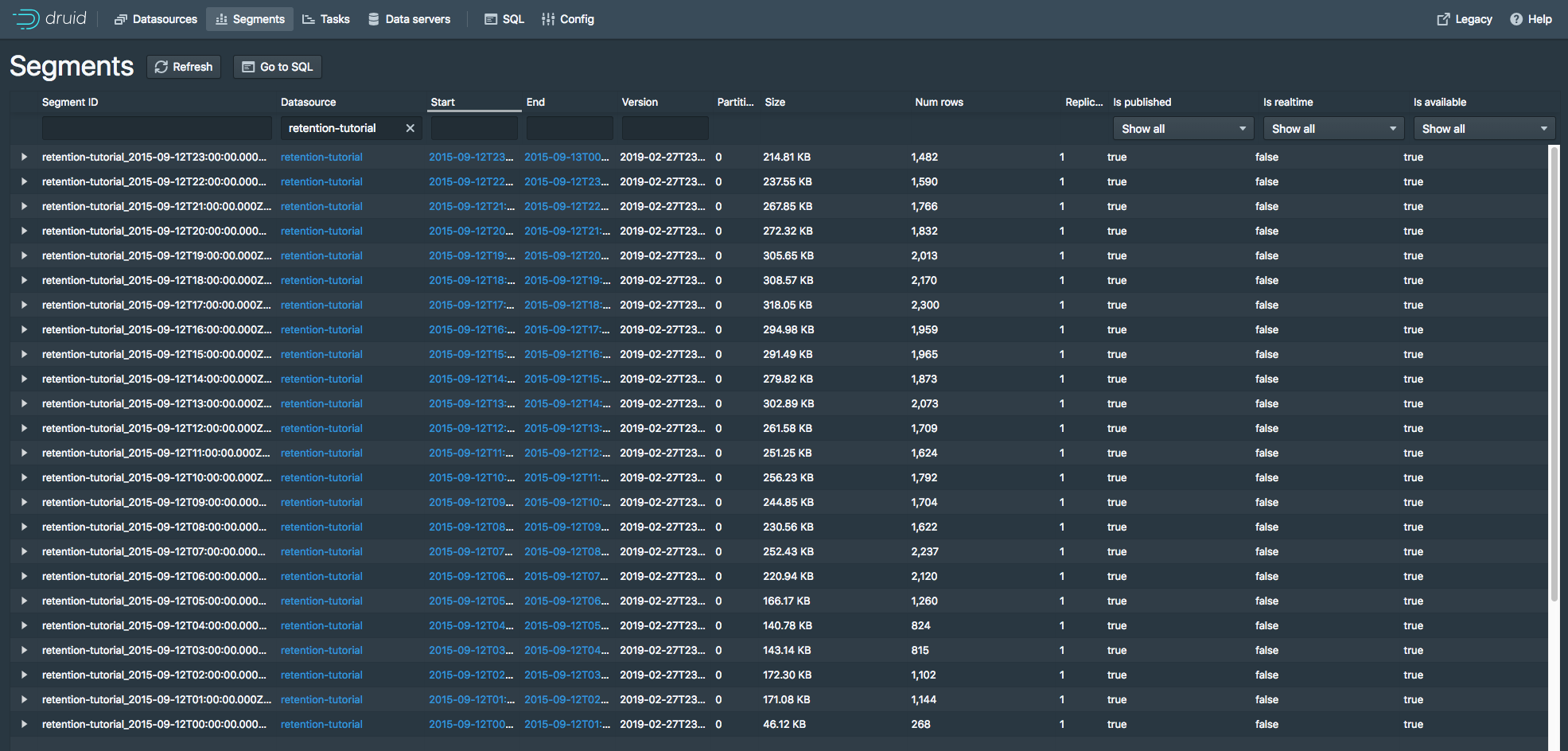
retention-tutorialCluster default: loadForever
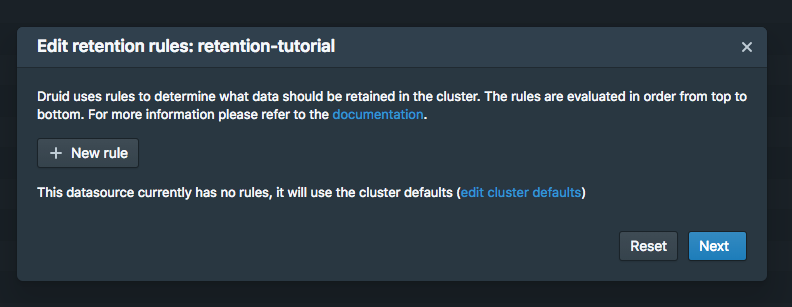
+ New rule
Loadby Intervalby Interval2015-09-12T12:00:00.000Z/2015-09-13T00:00:00.000Z_default_tier
Dropforever
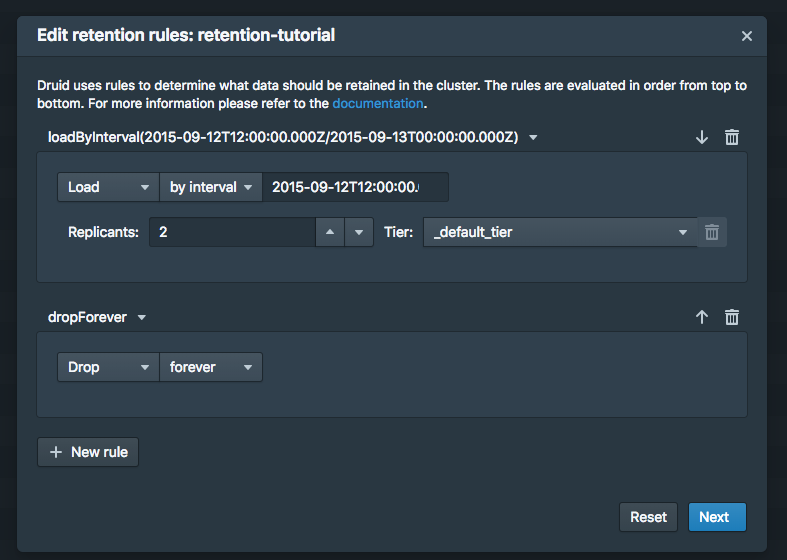
Next
Save

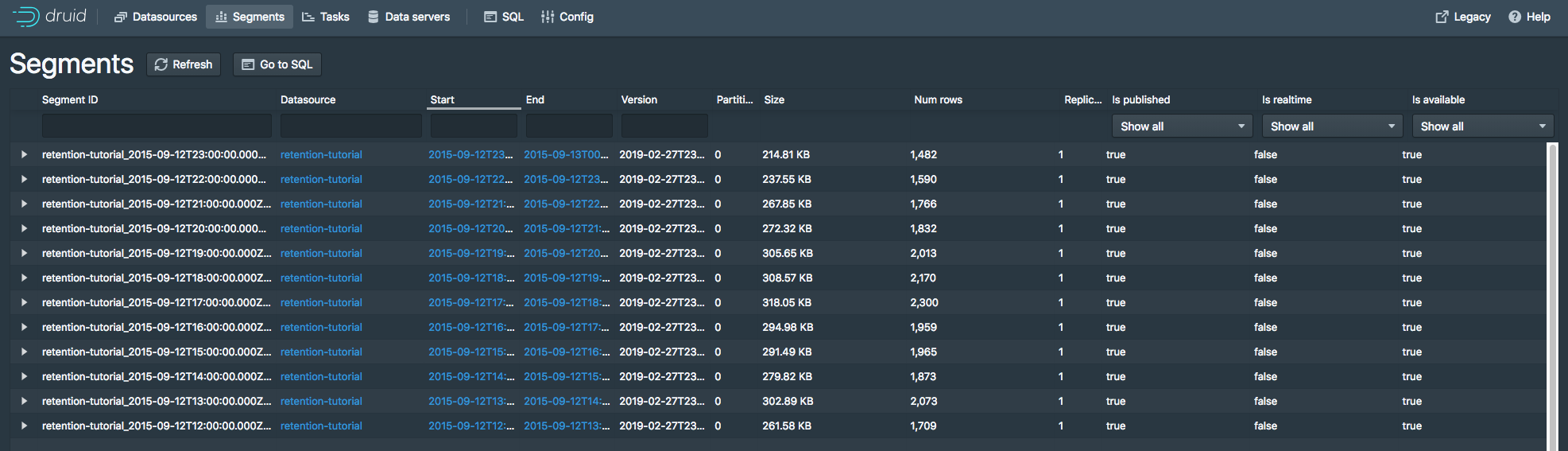
dropForeverdropForeverloadForever
注意
生命周期周期性

