- OLAP工具 - Druid导航
- Apache Druid 简介
- Apache Druid 下载安装
- Apache Druid 启动
- Apache Druid 集群部署
- Apache Druid 数据格式
- Druid入门指南 加载本地文件
- Druid入门指南 查询数据教程
- Druid入门指南 加载Kafka数据
- Druid入门指南 加载Hadoop数据
- Druid入门指南 Rollup操作
- Druid入门指南 配置数据保留规则
- Druid入门指南 数据更新
- Druid入门指南 合并段文件
- Druid入门指南 删除数据
- Druid入门指南 摄入配置规范
- Druid入门指南 数据过滤与转换
- Druid入门指南 Kerberized HDFS存储
- Druid架构设计 整体设计
- Druid架构设计 段设计
- Druid架构设计 进程与服务
- Druid架构设计 深度存储与本地挂载
- Druid架构设计 元数据存储
- Druid架构设计 Zookeeper
- Druid数据摄取 概述
- Druid数据摄取 数据格式
- Druid数据摄取 Schema设计
- Druid数据摄取 数据管理
Druid入门指南 合并段文件
quickstart/tutorial/compaction-init-index.jsoncompaction-tutorial
bin/post-index-task --file quickstart/tutorial/compaction-init-index.json --url http://localhost:8081 Copy
注意
http://localhost:8888/unified-console.html#datasources

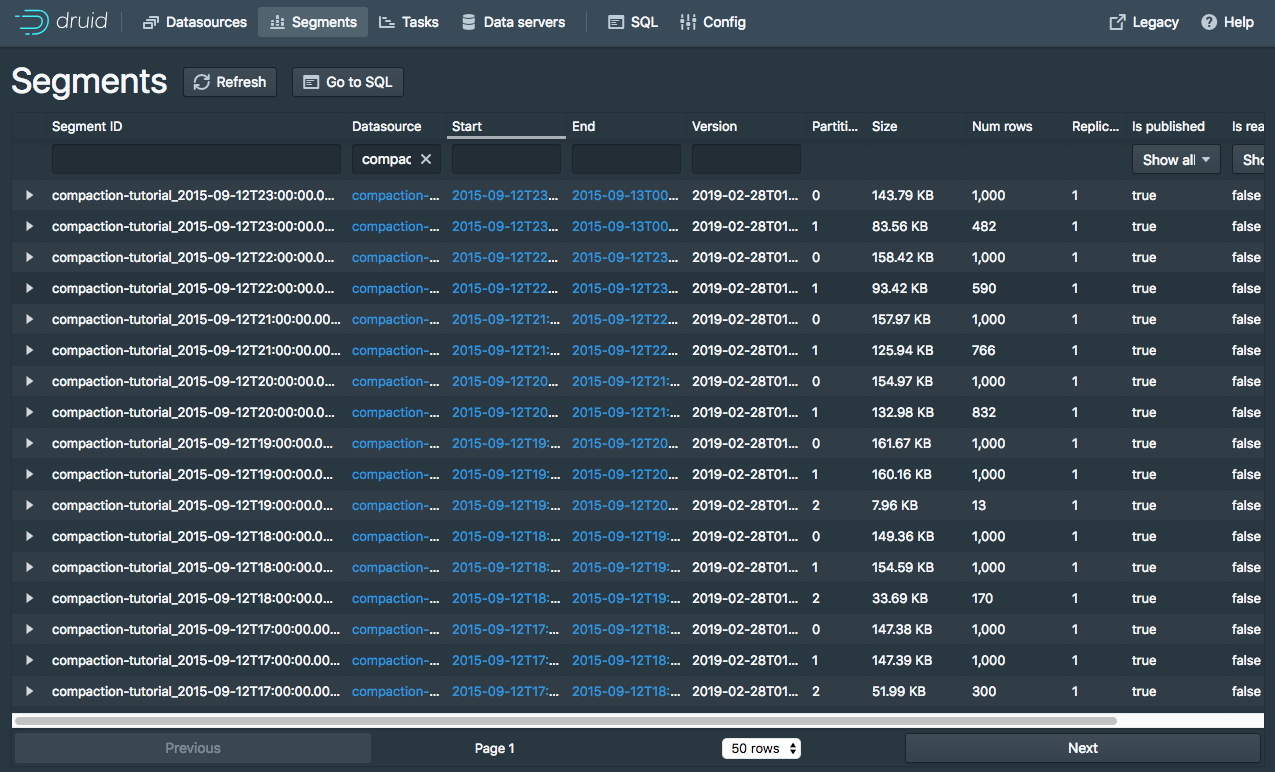
compaction-tutorial51 Segments
COUNT(*)
dsql> select count(*) from "compaction-tutorial";
┌────────┐
│ EXPR$0 │
├────────┤
│ 39244 │
└────────┘
Retrieved 1 row in 1.38s.
quickstart/tutorial/compaction-keep-granularity.json
{
"type": "compact",
"dataSource": "compaction-tutorial",
"interval": "2015-09-12/2015-09-13",
"tuningConfig" : {
"type" : "index_parallel",
"maxRowsPerSegment" : 5000000,
"maxRowsInMemory" : 25000
}
}2015-09-12/2015-09-13compaction-tutorialtuningConfig
bin/post-index-task --file quickstart/tutorial/compaction-keep-granularity.json --url http://localhost:8081
Segments
“未使用”合并段
旧数据段集合新合并集

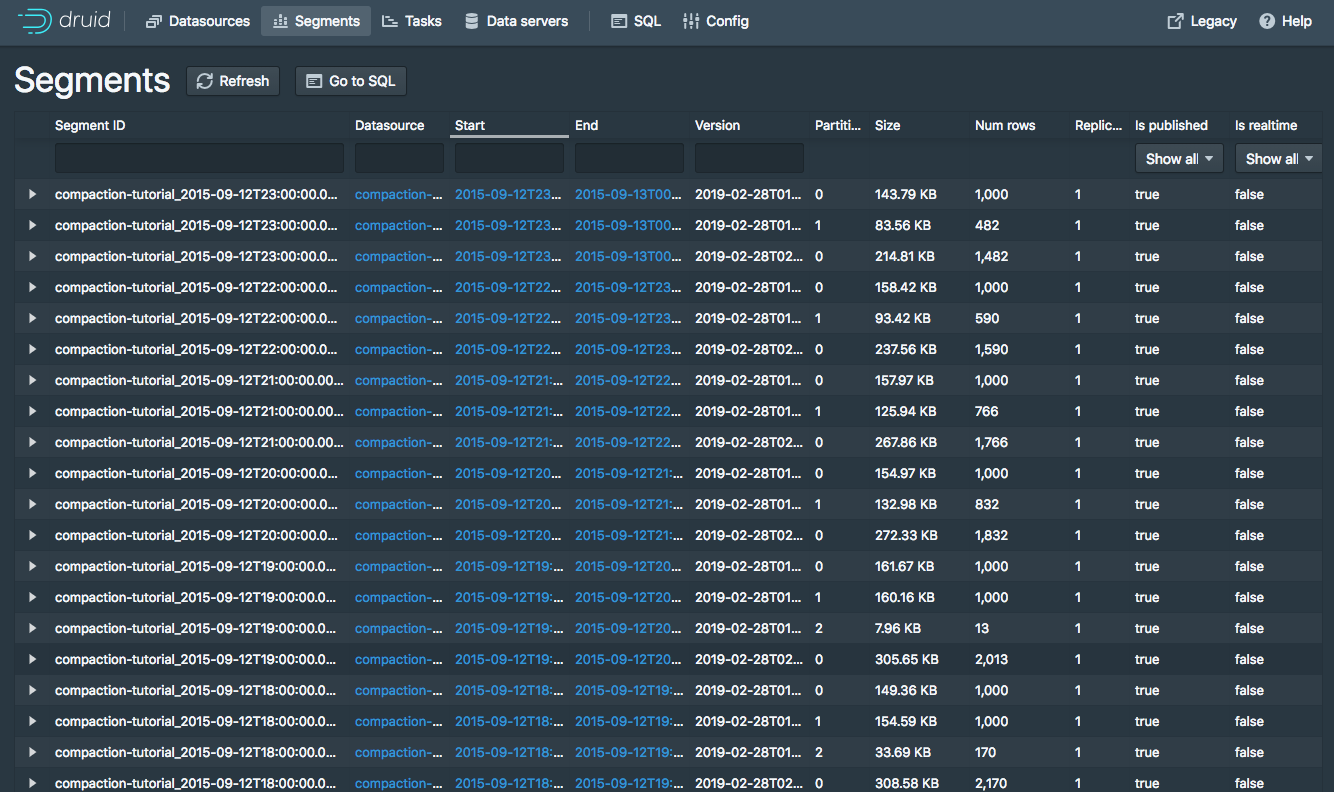
新的合并段
compaction-tutorialCOUNT(*)39244
dsql> select count(*) from "compaction-tutorial";
┌────────┐
│ EXPR$0 │
├────────┤
│ 39244 │
└────────┘
Retrieved 1 row in 1.30s.24个数据分段

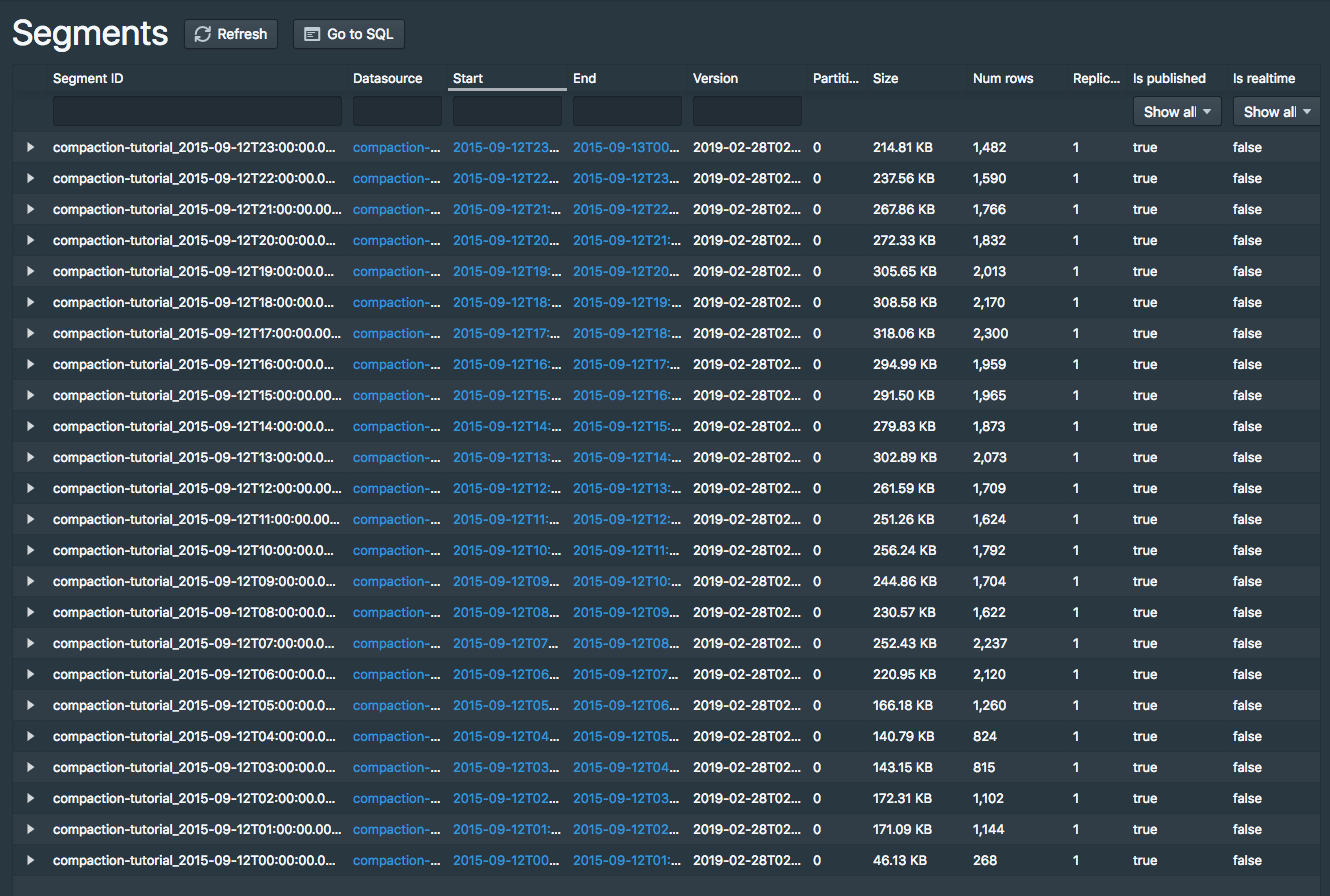
不同颗粒度
quickstart/tutorial/compaction-day-granularity.jsonDAY
{
"type": "compact",
"dataSource": "compaction-tutorial",
"interval": "2015-09-12/2015-09-13",
"segmentGranularity": "DAY",
"tuningConfig" : {
"type" : "index_parallel",
"maxRowsPerSegment" : 5000000,
"maxRowsInMemory" : 25000,
"forceExtendableShardSpecs" : true
}
}segmentGranularityDAY
bin/post-index-task --file quickstart/tutorial/compaction-day-granularity.json --url http://localhost:8081



