- ETL工具 - Kettle导航
- Kettle 增量同步
- Kettle 简介
- Kettle 安装与部署
- Kettle 运行界面与基本概念
- Kettle 读取CSV文件
- Kettle 导入文件夹下的多个文件
- Kettle 创建数据库连接
- Kettle 建立共享/停止共享数据库连接
- Kettle 表输入
- Kettle Excel输入
- Kettle 生成记录
- Kettle 生成随机数
- Kettle 获取系统信息
- Kettle 排序记录
- Kettle 去除重复记录
- Kettle 替换NULL值
- Kettle 过滤记录
- Kettle 值映射
- Kettle 字符串替换
- Kettle 字符串操作
- Kettle 分组
- Kettle 多线程数据优化
- Kettle windows定时调度作业
Kettle 多线程数据优化
这篇文章重点介绍多线程使用同步的配置思想,希望对大家有所帮助。
1 表输出的多线程实例。
步骤的多线程执行方法是通过设置步骤的“更改开始复制数量”属性来实现。如果是表格输出控件,选择”ChangeNunberofCopiestoStart..”,然后在Numberofcopies的输入框中填入并发的线程数量。
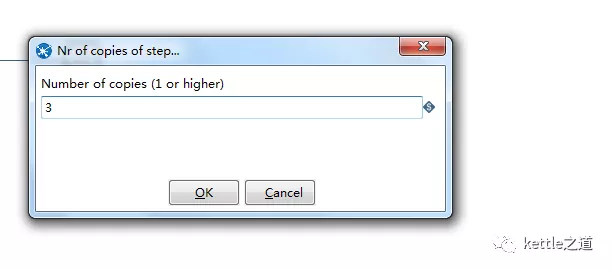
单向程测试:数据量10W,单线程14分钟。
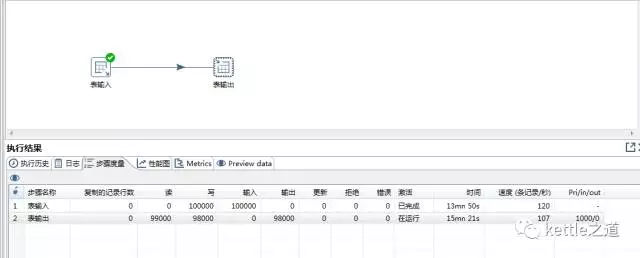
多线程测试:3线程7分钟的运行,效率加倍。“TableOutput这一步同时执行了3个线程,而TableInput则以轮询的方式将数据流按行发送到3个“表输出”线程。
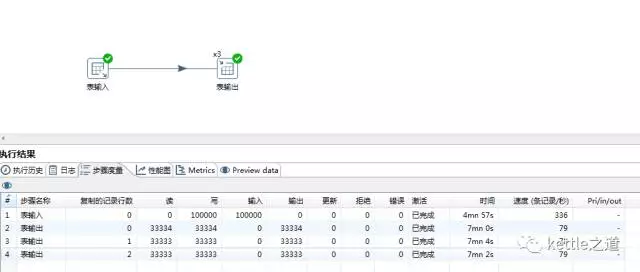
通过以上示例,您可以清楚地看到多线程相对于单线程而言效率的提升。
但是,在多线程”insert/update”场景中,如果更新的key并非惟一,则有可能产生死锁(多个线程一次更新同一行的数据)
通过以上示例,您可以清楚地看到多线程相对于单线程而言效率的提升。
但是,在多线程”insert/update”场景中,如果更新的key并非惟一,则有可能产生死锁(多个线程一次更新同一行的数据)
2 ODS概要

是完全提取还是递增式提取,同步化使用?
配置的示例:

其中一种是增量式的增量条件,另一种是完全抽取,不需要抽取条件。
3 实施步骤
1、从组态表中读取待提取的资料表。
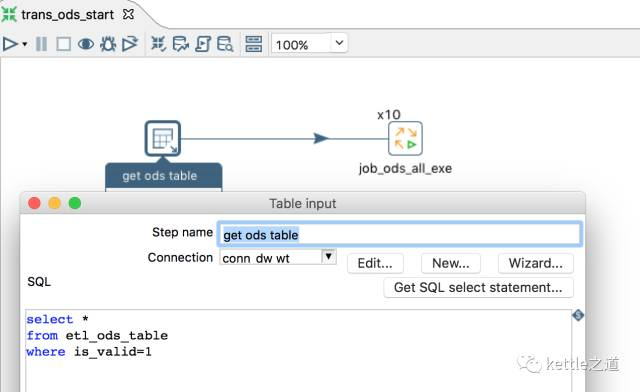
2、job_ods_all_exe同时执行10个线程,收到前一步传递的表名.数据库名称.提取类型等参数。
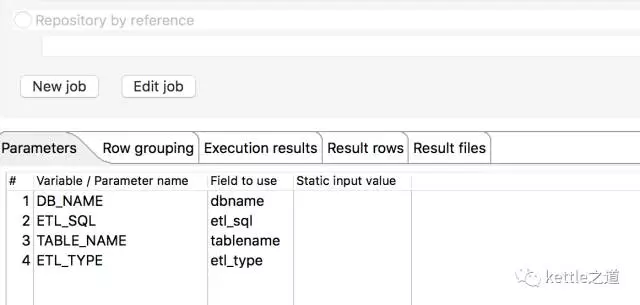
3、job_ods_all_exe,是否按ETL_TYPE分发数据是递增式提取还是完全抽取。
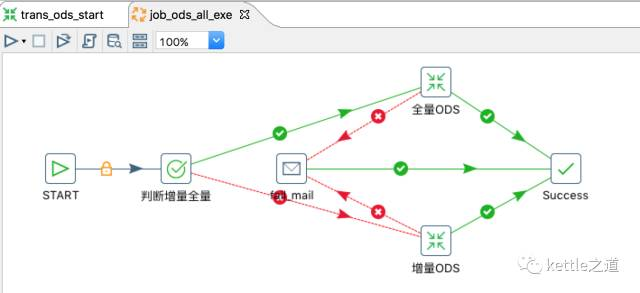
4、全量ODS和递增ODS实现逻辑:
二步是通过“表输入”步骤查询数据,全量是直接将表truncate为truncate,然后插入数据;deltaODS是使用插入更新的方式。
有两个必须插入一个更新控件:key.更新的字段,key可以将字段以传参的形式传递,需要扩展etl_ods_table表字段,配置源表的key,通常配置三个key字段就足够了;kettle自带的“insert/update”控件的update域是必选项,这是无法做到通用的,因为不可能所有同步表字段都是相同的,这需要定制插件,将updatefield变成必需项:
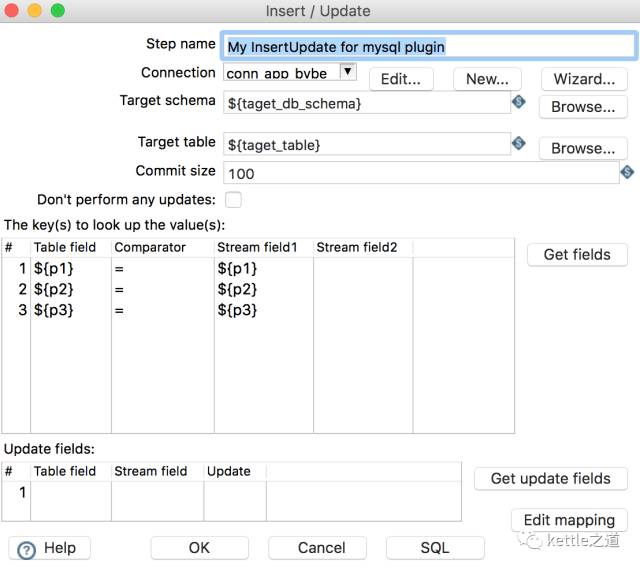
4 其他配置项目
1、目标表配置:为etl_ods_table表中为每一个同步表配置一个目标表,用一个变量来表示目标表用:${taget_db_schema}.${taget_table_name},因此,可重复使用组件,提高总体灵活性。
2、资料库连结:设定源表与目标资料表使用资料表连结,以参数化方式,以资料库连结方式,设定资料表结构:
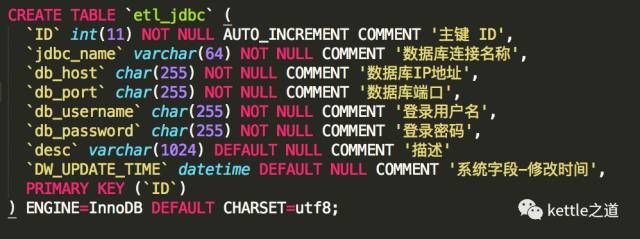
并且为etl_ods_table配置一个表,源表和目标表的数据量。据库连接的ID,查询同步表的信息时,数据库连接的也同时通过参数传递。


评论区(0)