MongoDB 快速入门
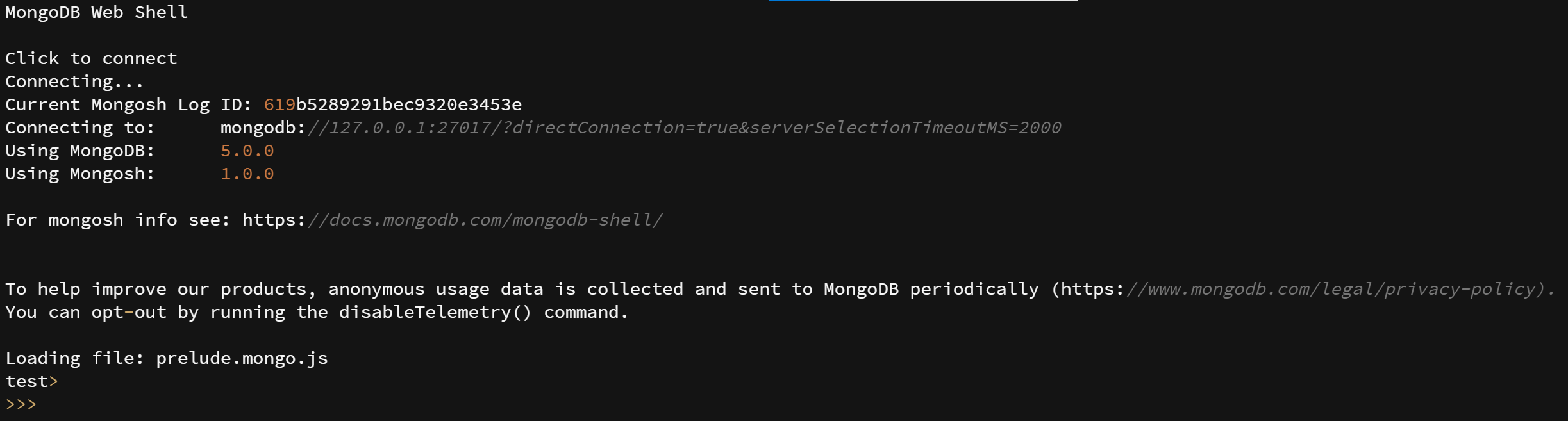
dbdb
test
use <db>examples
examples db
db.collection.insertMany()
db.movies.insertMany([
{
title: 'Titanic',
year: 1997,
genres: [ 'Drama', 'Romance' ],
rated: 'PG-13',
languages: [ 'English', 'French', 'German', 'Swedish', 'Italian', 'Russian' ],
released: ISODate("1997-12-19T00:00:00.000Z"),
awards: {
wins: 127,
nominations: 63,
text: 'Won 11 Oscars. Another 116 wins & 63 nominations.'
},
cast: [ 'Leonardo DiCaprio', 'Kate Winslet', 'Billy Zane', 'Kathy Bates' ],
directors: [ 'James Cameron' ]
},
{
title: 'The Dark Knight',
year: 2008,
genres: [ 'Action', 'Crime', 'Drama' ],
rated: 'PG-13',
languages: [ 'English', 'Mandarin' ],
released: ISODate("2008-07-18T00:00:00.000Z"),
awards: {
wins: 144,
nominations: 106,
text: 'Won 2 Oscars. Another 142 wins & 106 nominations.'
},
cast: [ 'Christian Bale', 'Heath Ledger', 'Aaron Eckhart', 'Michael Caine' ],
directors: [ 'Christopher Nolan' ]
},
{
title: 'Spirited Away',
year: 2001,
genres: [ 'Animation', 'Adventure', 'Family' ],
rated: 'PG',
languages: [ 'Japanese' ],
released: ISODate("2003-03-28T00:00:00.000Z"),
awards: {
wins: 52,
nominations: 22,
text: 'Won 1 Oscar. Another 51 wins & 22 nominations.'
},
cast: [ 'Rumi Hiiragi', 'Miyu Irino', 'Mari Natsuki', 'Takashi Naitè' ],
directors: [ 'Hayao Miyazaki' ]
},
{
title: 'Casablanca',
genres: [ 'Drama', 'Romance', 'War' ],
rated: 'PG',
cast: [ 'Humphrey Bogart', 'Ingrid Bergman', 'Paul Henreid', 'Claude Rains' ],
languages: [ 'English', 'French', 'German', 'Italian' ],
released: ISODate("1943-01-23T00:00:00.000Z"),
directors: [ 'Michael Curtiz' ],
awards: {
wins: 9,
nominations: 6,
text: 'Won 3 Oscars. Another 6 wins & 6 nominations.'
},
lastupdated: '2015-09-04 00:22:54.600000000',
year: 1942
}
])
db.collection.find()
db.movies.find( { } )db.collection.find()<field><value><field>: <value>
Christopher Nolan
db.movies.find( { "directors": "Christopher Nolan" } );
db.movies.find( { "awards.wins": { $gt: 100 } } );languagesJapaneseMandarin
db.movies.find( { "languages": { $in: [ "Japanese", "Mandarin" ] } } )db.collection.find(<query document><projection document>)
<field>: 1<field>: 0
idtitledirectorsyearmovies
db.movies.find( { }, { "title": 1, "directors": 1, "year": 1 } );_id0titlegenres
db.movies.find( { }, { "_id": 0, "title": 1, "genres": 1 } );$group
find()
genre
db.movies.aggregate( [
{ $unwind: "$genres" },
{
$group: {
_id: "$genres",
genreCount: { $count: { } }
}
},
{ $sort: { "genreCount": -1 } }
] )
$unwindgenres$group$countgenregenreCount$sortgenreCount

