- 综合知识导航
- 数据仓库略谈
- 智能制造定义及实现智能制造的意义
- 开源分布式数据库Hbase
- 数据库与大数据数据仓库区别
- MATLAB数据可视化
- 数据仓库简史及特点
- 浅谈如何在前端实现数据可视化热力图
- 18个数据可视化在生活中的应用
- 一文看懂:24种图表数据可视化的优缺点对比
- 10个数据可视化例子,让你更懂可视化
- 经典面试题:说说ETL的过程
- 15个惊艳业界的数据可视化作业案例
- 18篇最好看的数据可视化作品赏析
- 来了解一下数据可视化平台FineBl
- 数据可视化的过程有哪四个
- excel数据可视化图表制作
- 信息可视化设计用什么软件?一个工具,帮你实现酷炫的数据可视化
- FineBI——免费的数据可视化工具软件
- 帆软:做好企业发展的“导航”!
- 大数据数据仓库—概念
- 12个惊艳的数据可视化优秀案例
- 有趣好看的数据可视化图表怎么制作?
- R语言数据可视化分析怎么做
- 数据仓库管理系统与全链路数据体系
- 详解数据数据仓库有哪五层架构
- 数据统计可视化报表设计形式
- 商业智能软件市场 帆软何以独占鳌头?
- 大数据时代下的大数据舆情监测与分析
- 八大数据分析模型一览
- 数据可视化的工具有哪些
- 简述面向航空公司IT的“QAR数据分析系统”
- 数据仓库建模的三种模式
- 数据可视化图表怎么做才对
- 数据仓库的ETL、OLAP和BI应用
- 仓库管理系统选择指南
- 数据可视化需要了解什么
- 优秀的数据可视化怎么做的
- 五个数据分析可视化案例讲解
- 大数据可视化分析有哪四个步骤
- 如何利用插件制作Excel数据可视化图表
- 详解数据仓库搭建步骤
- 基于Hadoop的数据分析平台搭建
- 话说数据仓库分层4层模型
- Excel也有很强大的数据分析工具!
- 数据仓库概念及概述
- 数据挖掘实际案例——想上大学的有哪些人
- 优质数据分析报告的13个要点
- 来说数据仓库建模
- Python数据分析是干嘛的,需要哪些步骤?
- 闲说数据仓库理论上的范式
- 一文罗列数据集市和数据仓库的区别
- 数据分析之数据加工
- ELT数仓技术
- hive和hbase的区别有哪些
- 搭建hive运行环境详解
- 略讲数仓
- 大数据分析中,有哪些常用的大数据分析模型?
- 大数据分析中,有哪些常用的大数据分析模型?
- 数据分析技能
- 如何用R Markdown生成R语言数据分析报告
- 一文读懂基于大数据的数据仓库建设!
- 数据仓库发展趋势(1996-)
- 数据仓库的来源和发展
- 细讲ods数据仓库
- druid kylin 对比
- 数据仓库怎么建立需求?
- 听说过数据库,那数据仓库是做什么的
- 细说数据仓库与数据库的区别
- 开源数据仓库解决方案GreenPlum
- 如何构建数据仓库,本文细讲
- ETL处理流程与技术架构
- 数据治理ETL解决方案
- 数据仓库的多维数据模型设计
- olap与数据仓库的关系及区别
- SQL etl的数据指纹
- 数据仓库 数据湖的区别
- ETL是做什么?学习后有什么用?本文这就告诉你!
- 数据中台 数据仓库的区别
- 数据仓库的分层,你知道吗?
- 谈谈数仓etl系统建设
开源分布式数据库Hbase
1.开源分布式数据库系统HBase
HBase是一个开源分布式数据库,基于hadoop分布式文件系统,它的原型是google的BigTable分布式数据库。HBase是apache hadoop生态圈中的重要子项目之一。
HBase的设计目标是处理非常庞大的表,可以使用普通的计算机处理超过10亿行数据,并且有百万列元素组成的数据表。因此在文件在几百万行或者上千万行时不需要使用HBase。
在Hadoop生态圈中,HDFS为HBase提供了高可用性的底层存储支持,MapReduce为其提供了高可用性的计算能力,Hive和Pig提供了操作数据库的语言,zookeeper保证了分布式数据库的一致性要求,Sqoop提供了传统关系数据库的导入功能。它们都使得HBase的使用越来越广泛、越来越简单。下图为它们之间的关系。
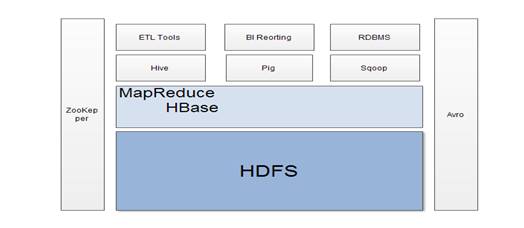
图一:Hadoop 生态圈中各个子项目之间的关系结构图
2.HBase的数据
数据模型是数据抽象的描述,是将现实中对象转化成数据的抽象过程。数据模型可以分为逻辑数据模型和物理逻辑模型。逻辑数据模型是设计人员对整个数据库的全面描述,描述的是数据和数据之间逻辑上的关系。所谓物理模型是数据库最低层的抽象,它描述数据在磁盘上的存储方式(文件的结构)、存储设备(外存的空间分配)和存取方法(主索引和辅助索引)。
HBase的逻辑模型
由于HBase是一个稀疏的、长期存储的、多维度的、排序的映射表。简单来说,应用程序是以表的方式在HBase存储数据的。表是由行和列构成的,所有的列式从属于某一个列族的。行和列的交叉点成为cell,cell是版本化的。Cell的内容是不可分割的字节数组。表的行键也是一段字节数组,所有任何东西都可以保存进去,不论是字符串还是数字。HBase的表是按key排序的,排序方式是针对字节的。所有的表都必须要有主键-key。
下面我们根据一个实例来讲解一下HBase的逻辑模型。下表是一个数据表的逻辑模型的逻辑视图。它表示的含义是,在一个网站中,每个网页的内容和锚点。
| 表一:逻辑视图 | |||
| Row Key | Time Stamp | ColumnFamily contents | ColumnFamily anchor |
| “com.cnn.www” | t9 | anchor:cnnsi.com=”CNN” | |
| “com.cnn.www” | t8 | anchor:my.look.ca=”CNN.com” | |
| “com.cnn.www” | t6 | contents:html=”<html>…” | |
| “com.cnn.www” | t5 | contents:html=”<html>…” | |
| “com.cnn.www” | t3 | contents:html=”<html>…” | |
表中参数解释
RowKey(行键)
行键是数据行在表中的唯一标识,是该记录的主键,相当于是关系数据库的主键。行键可以是任意字符串,最大长度为64KB,在HBase内部,行键保存为字节数组。存储时,数据按照行键的字典序(byte order)排序存储。设计key时,要注意排序存储这个特性,将经常一起读取的行存储放在一起。比如在电商中,行键设计为userId+url,这样的话,某个用户的访问路径就放在了一起,在推荐系统中可以方便的读取这些信息。在关系数据库中,主键是唯一标识的,不能重复的,在HBase中是不是也是如此呢?访问HBase table中的行时,通过行键访问或全表扫描。
列族
HBase表中的每个列都归属于某个列族。列名是由它的列族前缀额修饰符连接而成的。例如列contents:html是列族 contents加冒号(:)加修饰符html组成的。
时间戳
时间戳是HBase区别与传统关系数据库的重要特点。我们HDFS和HBase存储的都是流式数据。在HBase中进行update和delete操作时,实际上并没有将原来的数据进行更新和删除,而是插入新的数据,只是时间戳不同而已。HBase根据时间戳来判断哪个数据时最新的版本。时间戳的类型是64位的整型,默认情况下,它由系统根据当前时间自动生成,用户也可以设置时间戳。我们知道HBase是基于HDFS设计的,因此HBase的很多特性跟HDFS有密切的关系。
Cell
图中,一个个的单元格就是一个cell。HBase中的元素由行键、列和时间戳唯一确定,元素中的数据以字节码形式存储,没有特定的类型。cell是一个完整的部分,不能被分割。
HBase的逻辑模型是一个类似于稀疏矩阵的表格,它里面允许为空。
HBase的物理模型
尽管在概念逻辑视图中,表可以看成是一个稀疏的行的集合,但是在物理上,它是区分列族存储的。新的columns可以不经过声明直接加入一个列族。下面的表格是表一的物理视图。
| 表二:物理视图 | ||
| Row Key | Time Stamp | Column Family anchor |
| “com.cnn.www” | t9 | anchor:cnnsi.com=”CNN” |
| “com.cnn.www” | t8 | anchor:my.look.ca=”CNN.com” |
| “com.cnn.www” | t6 | contents:html=”<html>…” |
| “com.cnn.www” | t5 | contents:html=”<html>…” |
| “com.cnn.www” | t3 | contents:html=”<html>…” |
值得注意的是在上面的概念视图中空白的cell在物理上是不存储的,因为根本没有必要,而且存储的话会浪费大量的空间。因此若一个请求要获取t8时间的contents:html ,他的结果就是空。相似的,若请求为获取t9时间的anchor:my.look.ca,结果也是空。但是,如果不指明时间,将会返回最新时间的行,每个最新的都会返回。例如,如果请求为获取行键为”com.cnn.www”,如果没有指明时间戳的话,活动的结果是t6下的contents:html ,t9下的anchor:cnnsi.com和t8下的anchor:my.look.ca。
物理模型的特点是将不为空的cell存储起来。空白的就不再存储,不再是逻辑模式展示的矩阵的样子。
HBase数据模型与关系数据库的对比
在上面我们对HBase的逻辑模型和物理模型做了详细的介绍,总结一下HBase和传统关系数据库在逻辑模型和物理模型中的相同点和不同点。
| 表三:HBase和关系数据库的不同 | ||
| HBase分布式数据库 | 关系数据库 | |
| 逻辑模型 | 稀疏矩阵,比传统数据库多了一个时间戳 | 二维矩阵的形式 |
| 物理模型 | 由于数据库逻辑模型是一个巨大的稀疏矩阵,空cell是不存储的 | 矩阵全部存储 |

