- 综合知识导航
- 数据仓库略谈
- 智能制造定义及实现智能制造的意义
- 开源分布式数据库Hbase
- 数据库与大数据数据仓库区别
- MATLAB数据可视化
- 数据仓库简史及特点
- 浅谈如何在前端实现数据可视化热力图
- 18个数据可视化在生活中的应用
- 一文看懂:24种图表数据可视化的优缺点对比
- 10个数据可视化例子,让你更懂可视化
- 经典面试题:说说ETL的过程
- 15个惊艳业界的数据可视化作业案例
- 18篇最好看的数据可视化作品赏析
- 来了解一下数据可视化平台FineBl
- 数据可视化的过程有哪四个
- excel数据可视化图表制作
- 信息可视化设计用什么软件?一个工具,帮你实现酷炫的数据可视化
- FineBI——免费的数据可视化工具软件
- 帆软:做好企业发展的“导航”!
- 大数据数据仓库—概念
- 12个惊艳的数据可视化优秀案例
- 有趣好看的数据可视化图表怎么制作?
- R语言数据可视化分析怎么做
- 数据仓库管理系统与全链路数据体系
- 详解数据数据仓库有哪五层架构
- 数据统计可视化报表设计形式
- 商业智能软件市场 帆软何以独占鳌头?
- 大数据时代下的大数据舆情监测与分析
- 八大数据分析模型一览
- 数据可视化的工具有哪些
- 简述面向航空公司IT的“QAR数据分析系统”
- 数据仓库建模的三种模式
- 数据可视化图表怎么做才对
- 数据仓库的ETL、OLAP和BI应用
- 仓库管理系统选择指南
- 数据可视化需要了解什么
- 优秀的数据可视化怎么做的
- 五个数据分析可视化案例讲解
- 大数据可视化分析有哪四个步骤
- 如何利用插件制作Excel数据可视化图表
- 详解数据仓库搭建步骤
- 基于Hadoop的数据分析平台搭建
- 话说数据仓库分层4层模型
- Excel也有很强大的数据分析工具!
- 数据仓库概念及概述
- 数据挖掘实际案例——想上大学的有哪些人
- 优质数据分析报告的13个要点
- 来说数据仓库建模
- Python数据分析是干嘛的,需要哪些步骤?
- 闲说数据仓库理论上的范式
- 一文罗列数据集市和数据仓库的区别
- 数据分析之数据加工
- ELT数仓技术
- hive和hbase的区别有哪些
- 搭建hive运行环境详解
- 略讲数仓
- 大数据分析中,有哪些常用的大数据分析模型?
- 大数据分析中,有哪些常用的大数据分析模型?
- 数据分析技能
- 如何用R Markdown生成R语言数据分析报告
- 一文读懂基于大数据的数据仓库建设!
- 数据仓库发展趋势(1996-)
- 数据仓库的来源和发展
- 细讲ods数据仓库
- druid kylin 对比
- 数据仓库怎么建立需求?
- 听说过数据库,那数据仓库是做什么的
- 细说数据仓库与数据库的区别
- 开源数据仓库解决方案GreenPlum
- 如何构建数据仓库,本文细讲
- ETL处理流程与技术架构
- 数据治理ETL解决方案
- 数据仓库的多维数据模型设计
- olap与数据仓库的关系及区别
- SQL etl的数据指纹
- 数据仓库 数据湖的区别
- ETL是做什么?学习后有什么用?本文这就告诉你!
- 数据中台 数据仓库的区别
- 数据仓库的分层,你知道吗?
- 谈谈数仓etl系统建设
搭建hive运行环境详解
hive运行环境构建在hadoop运行环境的基础之上,为用户提供了一种用sql编写mapreduce分布式作业的方式。从写程序的角度看hive与mysql的区别几乎没有,几乎一致:都采用数据库和表对数据进行建模;都采用sql对数据进行操作;既支持直接通过命令行执行sql也支持jdbc等方式执行sql;最重要的不同有两点:hive不支持建立索引,但可以通过分区起到类似索引加速的作用;hive表里面的数据只能整体或者按分区覆写而不支持行级别更新。hive和mysql的区别更多的是在底层技术上,底层技术的不同又直接决定了两者面向的上层应用场景的不同。具体的hive和mysql的区别如下表所示:
| 底层技术 | 应用场景 | |||||
| 存储 | 索引 | 计算 | 实时写入 | 实时查询 | 海量大数据 | |
| mysql | 本地存储 | 支持索引 | 本地执行引擎 | 支持 | 支持 | 不支持 |
| hive | hdfs分布式存储 | 不支持索引,但支持按字段取值分区:比如按日期字段分区,数据会按照日期划分到不同的存储目录 | mapreduce分布式计算引擎 | 不支持,仅支持表级别或者分区级别的整体覆写 | 不支持,查询需要执行分布式作业,所以实时性较差 | 存储和运算都是分布式的天然支持含量大数据 |
hive的出现是为了降低原生mapreduce任务编写的复杂度,提高批处理分布式计算作业的开发效率。hive运行环境通过如下图所示组件与hadoop集群进行交互来达到这个目的:
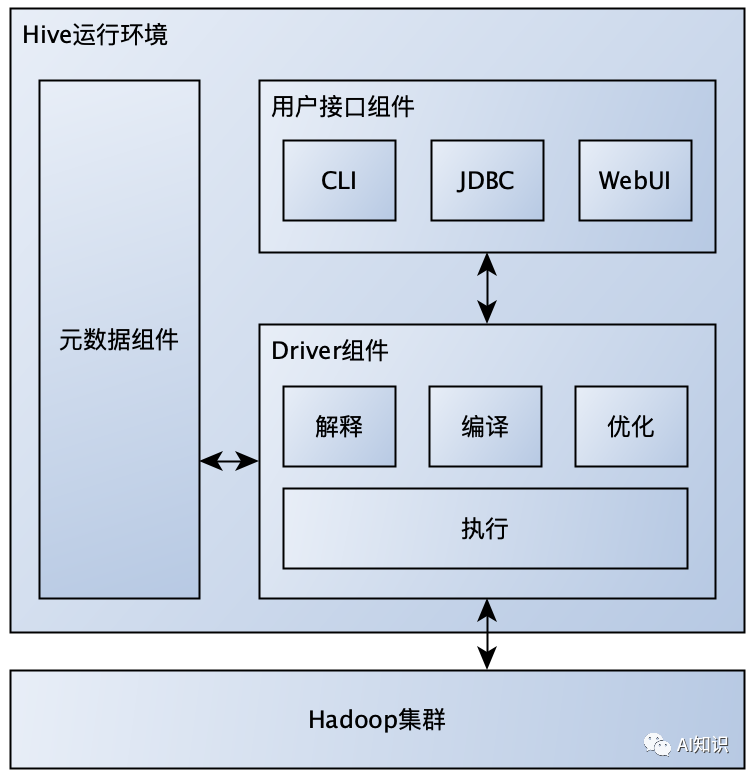
1,用户接口组件:提供CLI(命令行)、JDBC、WebUI等三种用户交互方式。
2,元数据组件:主要提供hive数据库、表以及分区到hadoop分布式存储路径映射关系的管理。
3,Driver组件:接收用户接口组件提交的sql,访问元数据组件进行必要的检查比如数据库表和分区是否存在等,校验通过之后通过解释器将sql转换成java代码,然后通过编译器将java代码编译成java字节码,再通过优化器对java字节码进行优化形成最终的mapreduce任务,最后通过执行器把mapreduce任务提交到hadoop集群执行,并把执行的结果返回给用户接口组件。
从上图所示的交互方式可以看出,Hive运行环境可以独立于hadoop集群进行部署,根据元数据组件部署方式的不同,hive运行环境有如下三种部署方式:
| hive运行环境部署方式 | 元数据组件 | 备注 | |
| 元数据服务 | 元数据存储 | ||
| 内嵌模式 | 内嵌元数据服务 | 内嵌数据库服务derby | 在1个进程内包含整个hive运行环境 |
| 本地模式 | 内嵌元数据服务 | 独立数据库服务mysql | 元数据存储独立到1个数据库服务进程中,在2个进程中包含整个hive运行环境 |
| 远程模式 | 独立元数据服务metastore | 独立数据库服务mysql | 再增加1个独立的metastore进程,代理对数据库服务的访问,在3个进程中包含整个hive运行环境 |
在正式介绍每种模式的部署方法之前,我们首先需要知道如何选择与hadoop集群兼容的hive版本,并准备好hive安装包。通过hive官网http://hive.apache.org/downloads.html,可以看到各hive版本兼容的hadoop版本,我们部署的hadoop集群是2.8.5,所以可以选择hive2.3.8。
首先介绍内嵌模式的部署方式。
步骤一:在hadoop集群局域网内选择一个ip,部署一个和集群节点相同配置的虚拟节点
docker run -d –privileged -h hive_emb –name hive_emb –net hadoopnet –ip 172.18.0.6 hadoop:v1.0 /usr/sbin/init
步骤二:登录刚部署的虚拟节点下载安装包
登录节点:docker exec -it hive_emb bash
备注:这里推荐先在宿主机上下载好安装包,然后通过docker cp apache-hive-2.3.8-bin.tar.gz hive_emb:/apps的方式拷贝的容器中,这样不用每次重新安装都需要下载一遍
步骤三:解压安装包并配置环境变量
解压安装包:tar -xvzf apache-hive-2.3.8-bin.tar.gz
配置环境变量:echo ‘export HIVE_HOME=/apps/apache-hive-2.3.8-bin
export PATH=$HIVE_HOME/bin:$PATH’ >> ~/.bashrc
使环境变量生效:source ~/.bashrc
步骤四:修改hive配置文件:包括hive-env.sh和hive-site.xml
进入配置目录:cd /apps/apache-hive-2.3.8-bin/conf/
配置hive-env.sh:cp hive-env.sh.template hive-env.sh && vim hive-env.sh,添加
HADOOP_HOME=/apps/hadoop-2.8.5
配置hive-site.xml:cp hive-default.xml.template /apps/apache-hive-2.3.8-bin/conf/hive-site.xml && vim hive-site.xml,整体替换为
<configuration>
<!–Hive中所有数据存储在HDFS上的路径–>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<!–连接本地Derby的Url–>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:derby:;databaseName=metastore_db;create=true</value>
</property>
<!–连接Derby的驱动包–>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>org.apache.derby.jdbc.EmbeddedDriver</value>
</property>
<!—元数据服务是否存放在本地,true代表存放在本地–>
<property>
<name>hive.metastore.local</name>
<value>true</value>
</property>
</configuration>
步骤五:初始化元数据库
schematool -dbType derby -initSchema
备注:执行完之后会在当前目录下看到数据库文件夹metastore_db
步骤六:验证是否搭建成功
启动hive命令行:hive
执行建表命令:create table test_table(id int);
查看表是否存在:show tables;
退出hive命令行:exit;
确认hdfs存在表目录:hadoop fs -ls /user/hive/warehouse/test_table
向表里面写入3条测试数据:echo -e “1\n2\n3” | hadoop fs -put -f – /user/hive/warehouse/test_table/d1
执行hive查询命令:hive -e “select sum(id) from test_table”,会在hadoop集群上执行分布式运算,最终输出6表示成功
再来介绍本地模式的部署方式。本地模式相对内嵌模式需要多部署1个数据库进程,数据库进程可以和hive部署到一台机器上,也可以部署在不同的机器上,我们采用部署到不同机器上。
步骤一:在hadoop集群局域网内选择一个ip,部署一个和集群节点相同配置的虚拟节点,用于部署mysql服务
启动虚拟节点:docker run -d –privileged -h mysql –name mysql –net hadoopnet –ip 172.18.0.7 hadoop:v1.0 /usr/sbin/init
登录虚拟节点:docker exec -it mysql bash
安装mysql源:rpm -Uvh http://dev.mysql.com/get/mysql-community-release-el7-5.noarch.rpm
安装mysql服务:yum -y install mysql-server
启动mysql服务:systemctl start mysqld.service
开机mysql自启:systemctl enable mysqld.service
授权所有ip可以通过root用户采用123456密码链接mysql:mysql -e “use mysql;grant all privileges on *.* to ‘root’@’%’ identified by ‘123456’ with grant option;flush privileges;”
步骤二:在hadoop集群局域网内选择一个ip,部署一个和集群节点相同配置的虚拟节点,用于安装hive运行环境
启动虚拟节点:docker run -d –privileged -h hive_local –name hive_local –net hadoopnet –ip 172.18.0.8 hadoop:v1.0 /usr/sbin/init
拷贝宿主机上的安装包到虚拟节点:docker cp apache-hive-2.3.8-bin.tar.gz hive_local:/apps
登录虚拟节点:docker exec -it hive_local bash
解压安装包:cd /apps && tar -xvzf apache-hive-2.3.8-bin.tar.gz
配置环境变量:echo ‘export HIVE_HOME=/apps/apache-hive-2.3.8-bin
export PATH=$HIVE_HOME/bin:$PATH’ >> ~/.bashrc
使环境变量生效:source ~/.bashrc
进入配置目录:cd /apps/apache-hive-2.3.8-bin/conf/
配置hive-env.sh:cp hive-env.sh.template hive-env.sh && vim hive-env.sh,添加
HADOOP_HOME=/apps/hadoop-2.8.5
配置hive-site.xml:cp hive-default.xml.template /apps/apache-hive-2.3.8-bin/conf/hive-site.xml && vim hive-site.xml,整体替换为
<configuration>
<!– hive和metastore服务是否在同一个节点 –>
<property>
<name>hive.metastore.local</name>
<value>true</value>
</property>
<!–mysql的数据库url–>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://mysql:3306/hive_remote?createDatabaseIfNotExist=true</value>
</property>
<!–连接mysql的驱动包–>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!–hive存放元数据的数据库的用户名–>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!–hive存放元数据的数据库的密码–>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
</configuration>
下载mysql jdbc驱动包:wget http://ftp.ntu.edu.tw/MySQL/Downloads/Connector-J/mysql-connector-java-5.1.49.zip
解压缩并放到hive的lib目录中:unzip mysql-connector-java-5.1.49.zip && mv mysql-connector-java-5.1.49/mysql-connector-java-5.1.49-bin.jar /apps/apache-hive-2.3.8-bin/lib
初始化元数据库:schematool -dbType mysql -initSchema
备注:执行完之后会在mysql数据库中创建hive_remote数据库。
步骤三:验证是否搭建成功
启动hive命令行:hive
执行建表命令:create table test_table(id int);
查看表是否存在:show tables;
退出hive命令行:exit;
确认hdfs存在表目录:hadoop fs -ls /user/hive/warehouse/test_table
向表里面写入3条测试数据:echo -e “1\n2\n3” | hadoop fs -put -f – /user/hive/warehouse/test_table/d1
执行hive查询命令:hive -e “select sum(id) from test_table”,会在hadoop集群上执行分布式运算,最终输出6表示成功。
最后介绍远程模式的部署方式。在本地模式的基础上再做两件事即可,一个是在已经部署好hive环境的节点hive_local上面,启动一个专门维护元数据库的服务metastore,另一个是再启动一个节点部署最终给终端用户使用的hive运行环境。下面分步介绍搭建过程:
步骤一:启动metastore服务
登录hive_local节点:docker exec -it hive_local bash
启动metastore服务:nohup hive –service metastore > metastore.log 2>&1 &
步骤二:在hadoop集群局域网内选择一个ip,部署一个和集群节点相同配置的虚拟节点,用于安装最终给终端用户使用的hive运行环境
启动虚拟节点:docker run -d –privileged -h hive_remote –name hive_remote –net hadoopnet –ip 172.18.0.9 hadoop:v1.0 /usr/sbin/init
拷贝宿主机上的安装包到虚拟节点:docker cp apache-hive-2.3.8-bin.tar.gz hive_remote:/apps
登录虚拟节点:docker exec -it hive_remote bash
解压安装包:cd /apps && tar -xvzf apache-hive-2.3.8-bin.tar.gz
配置环境变量:echo ‘export HIVE_HOME=/apps/apache-hive-2.3.8-bin
export PATH=$HIVE_HOME/bin:$PATH’ >> ~/.bashrc
使环境变量生效:source ~/.bashrc
进入配置目录:cd /apps/apache-hive-2.3.8-bin/conf/
配置hive-env.sh:cp hive-env.sh.template hive-env.sh && vim hive-env.sh,添加
HADOOP_HOME=/apps/hadoop-2.8.5
配置hive-site.xml:cp hive-default.xml.template /apps/apache-hive-2.3.8-bin/conf/hive-site.xml && vim hive-site.xml,整体替换为
<configuration>
<!– Hive文件HDFS存放路径 –>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<!– hive和metastore服务是否在同一个节点 –>
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
<!–metastore服务器的url,idea等外部可以通过metastore服务连接到hive,此处ip为部署metastore服务节点的ip–>
<property>
<name>hive.metastore.uris</name>
<value>thrift://172.18.0.8:9083</value>
</property>
</configuration>
步骤三:验证是否搭建成功
启动hive命令行:hive
查看表是否存在:show tables;
执行hive查询命令:select sum(id) from test_table;会在hadoop集群上执行分布式运算,最终输出6表示成功
退出hive命令行:exit; 至此,我们介绍完hive三种运行环境的搭建方式,下面简要总结一下这三种模式的区别和联系。内嵌模式元数据组件、用户接口组件以及Driver组件都在同一个进程内,不支持多个hive命令同时执行,因此只适合调试或者实验环境使用。本地模式三个组件依然在同一个进程内,只不过元数据组件里面负责存储元数据的数据库不再内嵌,而是独立出来单独部署一个进程,一般采用mysql数据库,这种模式能很好地支持多个hive命令同时执行,但是无法支持jdbc以及webUI等访问方式。远程模式把Driver和元数据这两个组件通过metastore服务暴露出去,不仅可以支持CLI访问,也支持jdbc和webUI等访问模式,是工业界使用比较普遍的部署模式。

