DataX是什么
DataX是阿里云DataWorks数据集成的开源版本,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台。DataX实现了包括MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、Hologres、DRDS等各种异构数据源之间高效的数据同步功能。
DataX的商业版本
- 阿里云DataWorks数据集成是DataX团队在阿里云上的商业化产品,致力于提供复杂网络环境下、丰富的异构数据源之间高速稳定的数据移动能力,以及繁杂业务背景下的数据同步解决方案。目前已经支持云上近3000家客户,单日同步数据超过3万亿条。
- DataWorks数据集成目前支持离线50+种异构数据源,可以进行整库迁移、批量上云、增量同步、分库分表等各类同步解决方案。2020年更新实时同步能力,支持10+种数据源的读写任意组合。提供MySQL,Oracle等多种数据源到阿里云MaxCompute,Hologres等大数据引擎的一键全增量同步解决方案。
- 商业版本参见: https://www.aliyun.com/product/bigdata/ide
DataX的框架设计
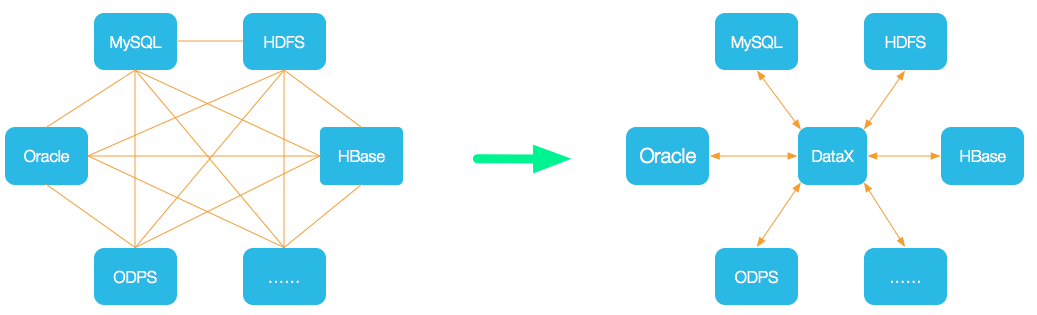
DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader / Writer插件,纳入到整个同步框架中。具体的概念请参考DataX 教程。
DataX的优势
1 可靠的数据质量监控
1)完美解决数据传输个别类型失真问题
DataX旧版对于部分数据类型(比如时间戳)传输一直存在毫秒阶段等数据失真情况,新版本DataX3.0已经做到支持所有的强数据类型,每一种插件都有自己的数据类型转换策略,让数据可以完整无损的传输到目的端。
2)提供作业全链路的流量、数据量运行时监控
在DataX3.0操作过程中,可以充分显示作业本身的状态、数据流、数据速度、执行进度等信息,使用户能够实时了解作业状态。此外,它可以在作业执行过程中智能地判断源端和目标端的速度对比情况,为用户提供更多的性能筛选信息。
3)提供脏数据探测
在大量数据的传输中,许多数据传输被错误报告(如类型转换错误),DataX认为该数据是脏数据。目前,DataX可以实现对脏数据的准确过滤、识别、收集和显示,为用户提供各种脏数据处理模式,使用户能够准确地控制数据质量标记!
2 丰富的数据转换功能
DataX作为一个服务于大数据的ETL工具,除了提供数据快照搬迁功能之外,还提供了丰富数据转换的功能,让异构数据在传输过程中可以轻松完成数据脱敏,补全,过滤等数据转换功能,另外还提供了自动groovy函数,让用户自定义转换函数。
3 精准的速度控制
还在为同步过程中对线程存储压力影响而担心吗?新版本DataX3.0提供了包括通道(并发)、记录流、字节流三种流控模式,可以随意控制你的作业速度,让你的作业在库可以在承受的范围内达到最佳的同步速度。
4 强劲的同步性能
DataX 3.0每一种读插件都有一种或多种切分策略,都能将作业合理切分成多个Task并行执行,单机多线程执行模型可以让DataX速度随并发成线性增长。在源端和目的端性能都足够的情况下,单个作业一定可以打满网卡。另外,DataX团队对所有的已经接入的插件都做了极致的性能优化,并且做了完整的性能测试。性能测试相关详情可以参照每单个数据源的详细介绍:https://github.com/alibaba/DataX/wiki/DataX-all-data-channels
5 健壮的容错机制
DataX作业是极易受外部因素的干扰,网络闪断、数据源不稳定等因素很容易让同步到一半的作业报错停止。因此稳定性是DataX的基本要求,在DataX 3.0的设计中,重点完善了框架和插件的稳定性。目前DataX 3.0可以做到线程级别、进程级别(暂时未开放)、作业级别多层次局部/全局的重试,保证用户的作业稳定运行。
6 极简的使用体验
1)易用
下载即可用,支持Linux和Windows,只需要短短几步骤就可以完成数据的传输、实现数据集成目的。
2)详细
DataX在运行日志中打印了大量信息,其中包括传输速度,Reader、Writer性能,进程CPU,JVM和GC情况等等。


评论区(0)